
Cómo personalizar ChatGPT y otros LLMs | RAG, Fine-tuning, y más


¿Te ha pasado que le has hecho una pregunta a ChatGPT sobre la actualidad y te contesta que no puede porque su “conocimiento” tiene un límite de tiempo?
También te pudo haber pasado que esperabas cierto estilo en su forma de responder.
Por ejemplo, si eres de Argentina, te debería ser natural que conteste con un vos en vez de tú, o bien con vosotros si eres de España.
Estos son problemas comunes de los modelos de lenguaje enorme o también llamados LLMs, que son la base detrás de herramientas como ChatGPT o Gemini.
Ve este contenido en formato video aquí
Esto se origina en el hecho de que estos modelos son entrenados sobre grandes conjuntos de datos para comprender y generar texto de manera coherente, pero que no necesariamente contiene información de todos los posibles campos, no predomina cierto estilo, y lo más importante, no es la más actualizada.
Sin embargo no todo está perdido. Existen enfoques, algunos más complejos que otros, para ajustar y personalizar los LLMs. De esta manera, podemos lograr que entreguen respuestas más relevantes y específicas, o de un estilo en particular que queramos, y así logramos mejorar la experiencia del usuario final.
Me atrevería a decir que estos enfoques son, a día de hoy, los más usados en la industria y estudiados en la academia:
- Prompt Engineering
- RAG
- Function Calling
- Fine-tuning.
Cada uno de ellos no está exento de dificultades y desafíos.
¡Pero no te preocupes! En este video te ayudaremos a entender de qué se tratan para que aprendas a elegir el que haga más sentido para tu problema.
¡Comencemos!
Prompt Engineering
El más sencillo de los métodos es el Prompt Engineering, o ingeniería de instrucciones, el cual se refiere al proceso de diseñar y refinar las indicaciones o "prompts" que se le dan a un modelo de lenguaje para mejorar la calidad y relevancia de sus respuestas.
Este método no requiere modificar el modelo subyacente o su entrenamiento; en su lugar, se enfoca en cómo se formula la solicitud al modelo para guiarlo hacia respuestas más precisas y útiles.
Es especialmente útil en situaciones donde el fine-tuning, o métodos más intensivos en recursos, que veremos más adelante, no son viables. Puede ser efectivo para ajustar el tono, estilo, o enfoque de las respuestas del modelo.
Por ejemplo, puedes añadir instrucciones para que un modelo te pueda contestar formalmente o para que “suene” más cercano, así como lo hablamos al principio de este video.
Otro ejemplo es indicarle un enfoque de cómo abordar preguntas que requieren ciertas maneras de encontrar la respuesta correcta.
¡Así de sencillo!
El prompt engineering es generalmente menos costoso en términos de recursos computacionales y tiempo, en comparación con el fine-tuning o RAG.
Sin embargo, requiere mucho proceso de prueba y error para perfeccionar los prompts. Además, lo que funciona en cada modelo puede ser MUY distinto. Pero hay ciertos tips que son importantes y aplicables en general para cualquier modelo.
Si deseas aprender a hacer un buen prompt, te recomendamos este post.
 EvoAcademy
EvoAcademy
RAG: Retrieval-Augmented Generation
El siguiente método de nuestra lista es el RAG (Retrieval-Augmented Generation), o la generación mejorada por recuperación.
Combina la generación de texto de un LLM con la recuperación de información de una base de datos o un conjunto de documentos específicos.
Esto permite que el modelo cree respuestas que no solo se basan en su conocimiento previamente entrenado, sino también en datos específicos y actualizados, como una base de datos de tu empresa o algún documento en particular de interés.
Es ideal para aplicaciones donde la precisión de la información es crítica y alucinar tiene un costo muy alto. Por ejemplo, un chatbot de soporte al cliente.
En este caso, RAG permitiría al modelo extraer y sintetizar información de documentos técnicos o bases de datos especializadas.
También sería útil cuando es necesario acceder a la última versión disponible sobre un dato, como podría ser en un sitio de comercio electrónico, donde sólo se le debe sugerir al cliente aquellos productos que estén disponibles en el inventario.
Implementar un RAG no es algo sencillo. Aquí podrás ver una arquitectura básica de un RAG
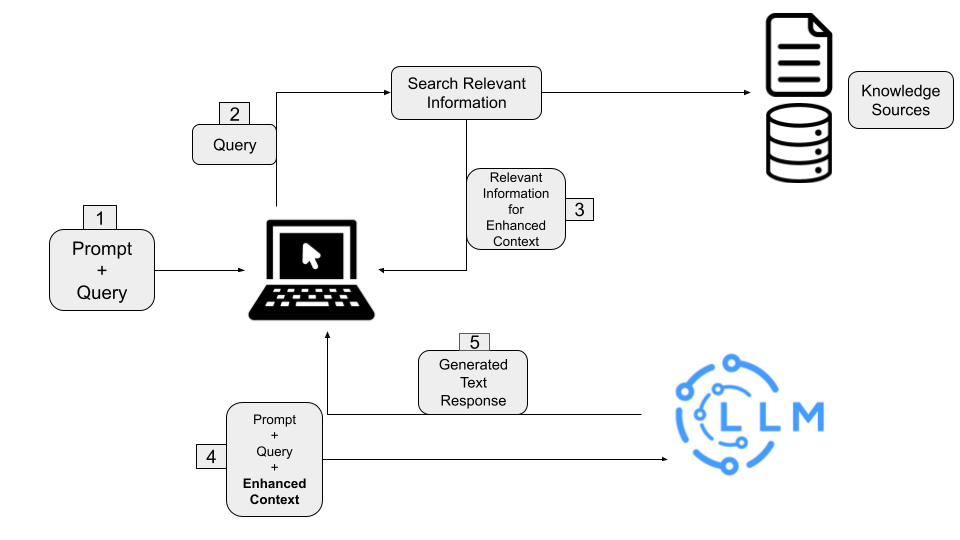
Como ves, conecta muchas partes. Además, entra un juego un segundo componente: el Retriever
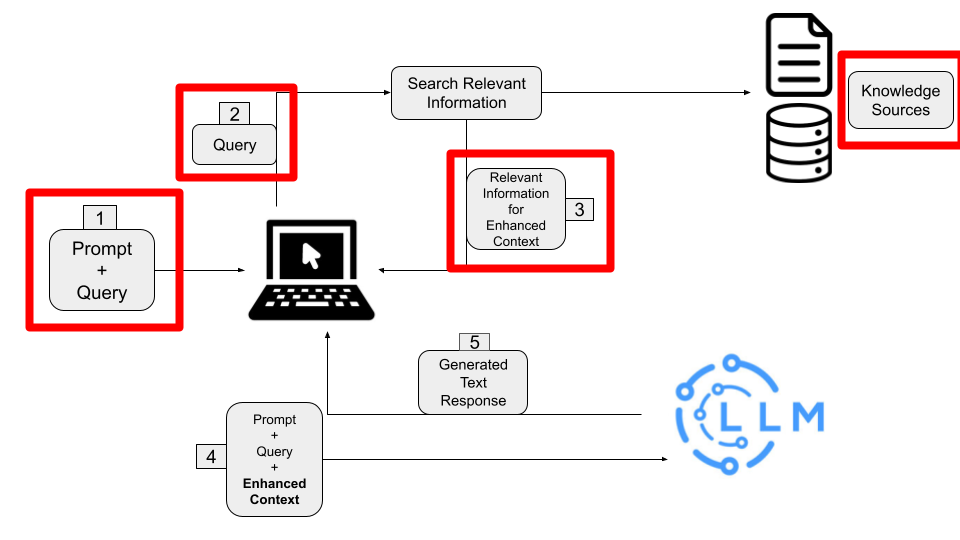
El cual se encarga de buscar la información relevante en base a la pregunta que está enviando el usuario.
De esta manera, antes de que el prompt sea enviado al LLM, el Retriever mejora el contexto del prompt agregando la información relevante que encontró.
Pero para poder hacer esto, hay varios procesos antes que se deben realizar.
Por un lado, los datos a los cuales el Retriever accede deben ser procesados y convertidos a “Embeddings”, los cuales son representaciones numéricas de la información, o técnicamente vectores. Estos números deben ser guardados en una base de datos, la cual se conoce como base de datos vectorial.
Esta conversión a Embeddings también se aplica a la pregunta que se le pretende hacer al LLM, para que luego, tanto los Embeddings de la pregunta y de la base de datos puedan ser comparados, y así seleccionar de manera eficiente los pedazos de información más relevantes guardados en la base de datos vectorial.
¿Suena complicado? En este podcast te explicamos en detalle en qué consiste el RAG, pero, cómo verás, requiere muchas partes para poder funcionar.
Si al esquema del inicio le añades controles de ciberseguridad, y más capas de análisis, puede ser aún más complejo, pero es la mejor alternativa para tener acceso a datos privados, específicos y actualizados.
Function Calling
Otro método de personalizar tu LLM es con el uso de Function Calling, o llamado de funciones.
Este permite al LLM indicar cuándo gatillar llamados a funciones u otras API durante la generación de texto, integrando respuestas dinámicas basadas en información más allá del conocimiento interno del LLM.
Un ejemplo de esto es cómo opera el modelo DALL-E 3. Para usarlo, debes ir a ChatGPT 4, la versión de pago de ChatGPT, y pedirle que te cree una imagen.
Lo que está pasando es que ChatGPT, luego de recibir el prompt, determina que necesita llamar a la función (de ahí el nombre de “Function Calling”) que se conecta DALL-E 3, identificando los “argumentos” que debe entregarle a esa función.
Luego, se gatilla el llamado, y se espera hasta que DALL-E 3 responda con la imagen generada.
Finalmente, ChatGPT usa el resultado del llamado de esta función y genera la respuesta.
Este método es útil para aplicaciones basadas en LLM que requieren interacción con sistemas externos, tales como realizar reservaciones, consultar el clima, o interactuar con bases de datos dinámicas externas.
Nota que cada una de estas interacciones tiene una estructura específica de hacerse, y que generalmente es por medio de APIs o funciones programadas internamente.
Si no sabes lo que es una API, puedes revisar este video donde te explicamos en sencillo qué es:
Esto implica que para sacar provecho a Function Calling, se necesita trabajo adicional para ejecutar la acción que el LLM está solicitando realizar. Esto podría ser una desventaja cuando deseas usar este enfoque, ya que si no tienes los conocimientos necesarios, será muy difícil de implementar completamente.
Fine–tuning
Finalmente, tenemos el método de Fine-tuning, o ajuste detallado.
Este método implica el entrenamiento adicional de un LLM pre-entrenado, como los que existen detrás de ChatGPT: GPT4 o GPT3.5, el modelo OpenSource de Meta: LLaMA, u otros, para adaptar su generación de texto a un dominio o tarea particular.
El entrenamiento de un modelo por medio de fine-tuning no es una tarea sencilla. Generalmente, demanda un alto consumo de recursos computacionales y requiere de conocimientos previos en entrenamiento de modelos para su correcta configuración, adquiridos en campos como el Aprendizaje Automático (Machine Learning) y el Aprendizaje Profundo (Deep Learning). Además, requiere conjuntos de datos de entrenamiento de alta calidad y específicos del dominio.
Sin embargo, es el único de estos métodos que modifica el LLM desde dentro, permitiendo una mejor dirección del modelo. Si te interesa un poco más, te dejamos un link a un tutorial que hicimos hace un tiempo para realizar fine-tuning a GPT3.5, el modelo detrás de la versión gratuita de ChatGPT.
¿Cuándo usar fine-tuning?
En general es efectivo para aplicaciones que requieren que el LLM produzca texto con un estilo de comunicación particular, o bien seguir adecuadamente un formato de respuesta, como transformar texto a un formato JSON.
Algunas herramientas te permiten hacer versiones simplificadas del fine-tuning, como el Parameter-efficient fine-tuning (PEFT), el cual modifica una pequeña parte de todo el modelo, pero que puede entregar resultados comparables al fine-tuning regular, a sólo una fracción del costo. Si estás interesado en esto, te dejamos un link bastante interesante a Hugging Face.

Comparación y selección
La elección entre estos métodos depende de varios factores, incluyendo la naturaleza de la tarea, los recursos disponibles, y los objetivos específicos de personalización.
El Prompt Engineering suele ser suficiente para ajustar levemente el modelo, y es ideal cuando el problema requiere una rápida resolución.
Por otro lado, Function Calling se destaca en aplicaciones que requieren interacción con sistemas externos o datos en tiempo real.
Mientras que el RAG es ideal para cuando la actualidad y precisión de la información es primordial.
Finalmente, Fine-tuning es preferible para direccionar el modelo hacia ciertos estilos y tareas específicas que buscan un formato específico de respuesta, tales como en dominios con alta precisión lingüística o transformar texto a JSON.
Es importante destacar que estos métodos no son excluyentes. Los sistemas más sofisticados combinan muchas de estas técnicas, aprovechando así las ventajas de cada una de ellas. Si éste es el enfoque que buscas, nuestra recomendación es empezar con prompt engineering, y luego ir complementando con otros métodos.
Esperamos que éste post les haya ayudado a entender más sobre el fascinante mundo de la personalización de los modelos de lenguaje.
