
¿Cómo crear voces con IA como la de Bad Bunny? | Tutorial de Kits AI
En este tutorial aprenderás como se clonan las voces utilizando Inteligencia Artificial y Kits AI


En el último tiempo se han creado muchas canciones con Inteligencia Artificial. De seguro la más famosa es NostalgIA de FlowGPT, la cual originalmente imitaba la voz de Bad Bunny.
@javierlyricsoficial CANCIÓN IA DE BAD BUNNY😍 #badbunny #badbunnypr #benito #benitomartinezocasio #musicaia #inteligenciaartificial #ia #trap #reggaeton #rolas #rolitas #lyrics #videoslyrics #javierlyrics_
♬ sonido original - 𝙅𝙖𝙫𝙞𝙚𝙧 𝙇𝙮𝙧𝙞𝙘𝙨
TikTok con el extracto de NostalgIA, la canción de FlowGPT, con la voz de Bad Bunny
Luego de eso, y en reacción al enojo de Bad Bunny por NostalgIA, se han creado muchas canciones con Inteligencia Artificial imitando la voz del conejo malo.
@user666j #badBunny #ia #viral #polemica #fyp #music
♬ sonido original - 𝕵𝖆𝖛𝖎𝖊𝖗𝖆🦋
TikTok con una compilación de temas creados con Inteligencia Artificial usando la voz de Bad Bunny
O quizás has escuchado los mensajes de aliento que la gente hace con la voz de la estrella del fútbol Cristiano Ronaldo.
@the.bug07 🫂siempre con la frente en alto. #frasesmotivadoras #cristianoronaldo #cr7 #fyp #fypシ #parati #thebug #paradedicar
♬ sonido original - The Bug
Uno de los cientos de TikTok con la voz de Cristiano Ronaldo donde la estrella del fútbol te alienta a salir de las adversidades
¿Pero cómo se crean estas voces? ¿qué es lo necesario y qué herramientas se usan? En el siguiente artículo te lo explicamos.
Video
Puedes ver este contenido en video aquí
Cómo funcionan las IA de voz
Existen dos modos en los cuales estas plataformas crean voces con Inteligencia Artificial: de voz a voz, y de texto a voz. Para ambos modos los pasos son parecidos pero en este tutorial nos enfocaremos en los de voz a voz.
Voz a voz
El modo voz a voz, o también conocidas como discurso a discurso por su traducción literal del inglés speech to speech, quiere decir que tú le entregas un audio al modelo de Inteligencia Artificial con tu voz original y este modifica tu audio para convertirlo en uno que pareciera haberse dicho con la voz clonada.
De cierto modo se podría decir que la Inteligencia Artificial juega el mismo rol que juegan los sintetizadores que hacen posibles el auto-tune u otros refinamientos de voz pues cambia la voz original para ajustarse a un tono parecido al de otra persona.
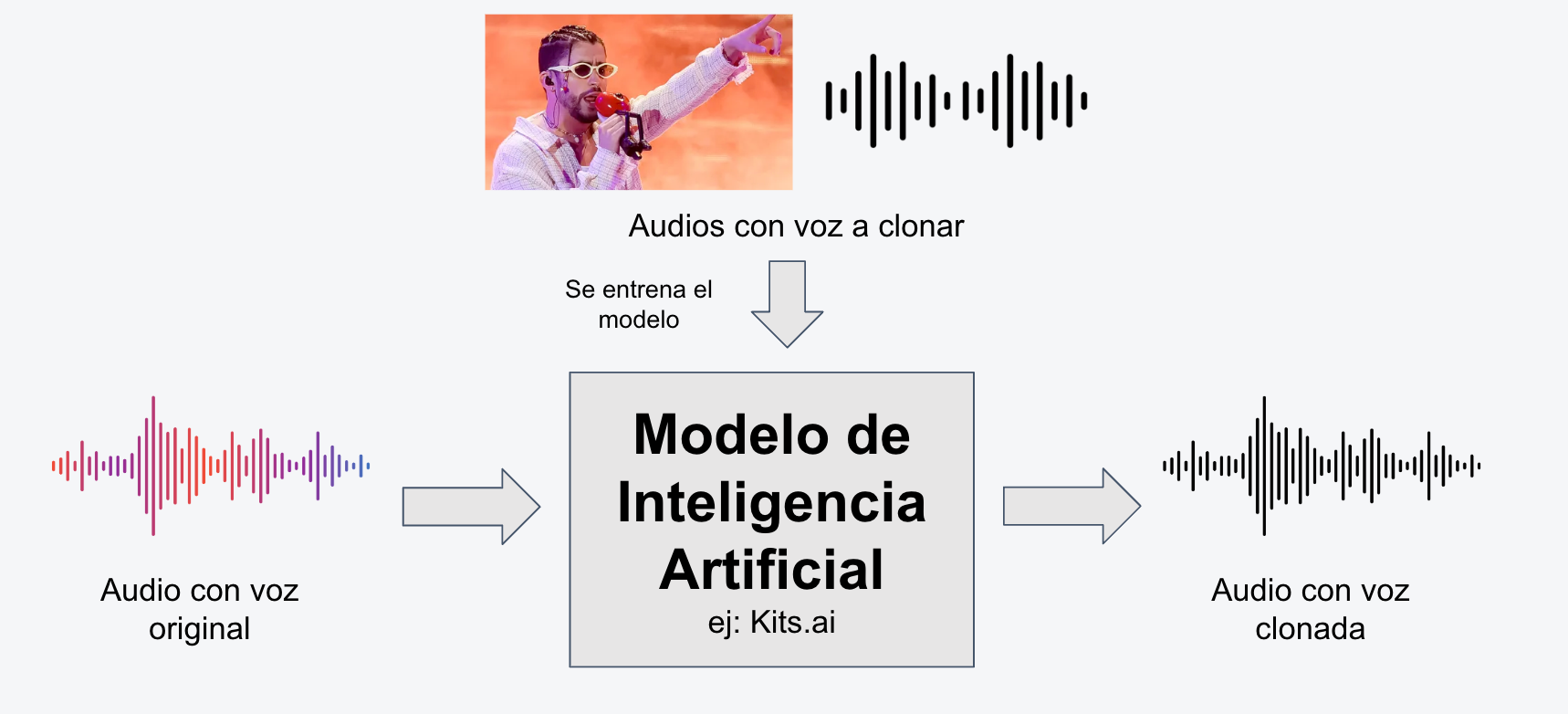
En este ejemplo yo canté una parte de la canción infantil "los pollitos dicen" y le pedí a la herramienta lo cambiar a la voz clonada de Bad Bunny.
Texto a voz
El modo de texto a voz, o texto a discurso, le entregamos un texto al modelo de Inteligencia Artifical y el robot determina como este se debe vocalizar.
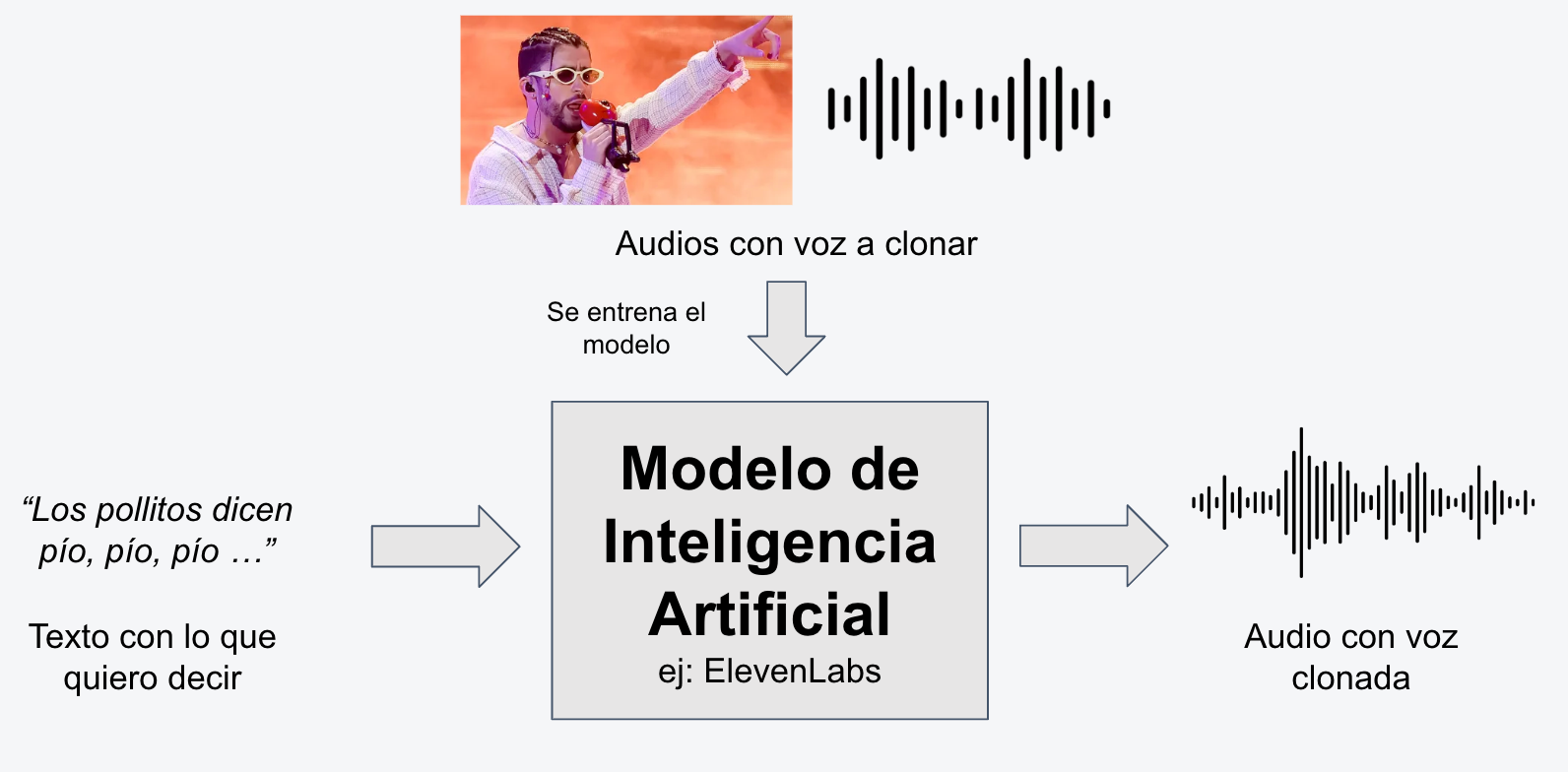
La herramienta más conocida de texto a voz es ElevenLabs, de la cual hablaremos en otro tutorial pues no tiene tan buenos resultados para el caso de uso que estamos viendo en este tutorial.
En este ejemplo le entregué el mismo texto que dije en el audio anterior al modelo y me entregó esto.
Como pueden escuchar, este tipo de modelos si bien son preciso carecen de las sutilezas en pronunciación y entonación que muchas veces los artistas hacen en sus canciones, por ello no son tan adecuados para hacer música.
Cómo crear los audios de entrenamiento
Para ambos modos debemos entrenar la Inteligencia Artificial con audios de la voz a clonar, en los modelos esto se conocen como "samples".
Cómo limpiar los audios
Estos audios deben ser "limpios", es decir sólo debe contener audio de la persona hablando o cantando. Es decir no puede haber ruido en el fondo, tales como melodías, aires acondicionados, otras conversaciones, y más.
Además se debe eliminar risas, respiraciones, y otros sonidos que no contribuyan al modelo a entender como el usuario pronuncia normalmente.
Si bien limpiar las risas y otros similares es fácil pues simplemente eliminas aquellos segundos donde ocurren, separar la melodía de la voz es un proceso más difícil. Para eso, yo utilicé el Voice Isolator de DaVinci Resolve Studio, pero existen muchas herramientas para esto.
En la siguiente imagen pueden ver en la primera fila la onda de sonido de la canción Yonaguni de Bad Bunn. Mientras que en la segunda pueden ver el resultado luego de que la limpié.

Por ejemplo este es una parte sin ninguna edición
Y esto es luego de trabajada del modo descrito anteriormente
Este último archivo se puede seguir perfeccionando, pero este nivel ya es suficientemente bueno.
Lo último que se debe hacer es eliminar los espacios sin audio
¿Cuánta información se necesita?
En general mientras más audios tengas mejor, pero en la mayoría de las herramientas a utilizar el resultado no mejora de modo importante después de darle más de 5 minutos de información.
Los audios deben ser representativos
Lo más importante es que estos audios sean representativos de lo que quieres clonar.
Es importante destacar que no es lo mismo hablar que cantar. Es decir, si quieres clonar a alguien hablando (como en el caso de Cristiano Ronaldo), es distinto a si quieres clonar a alguien cantando (como en los ejemplos de Bad Bunny). Lamentablemente no puedes hacer que alguien que está hablando en sus audios pase a cantar y viceversa.
Además, si quieres generar audios de una persona hablando un idioma lo ideal es que los audios de entrenamientos sean de la persona hablando en ese idioma. Te sorprendería ver como las personas pueden cambiar sus acentos al cambiar de idioma.
Generación de la voz
Existen varias plataformas para lograr algo así, en este tutorial vamos a usar la que utilizó Mauricio, el creador de FlowGPT, para crear NostalgIA.
Crea una cuenta en Kits AI
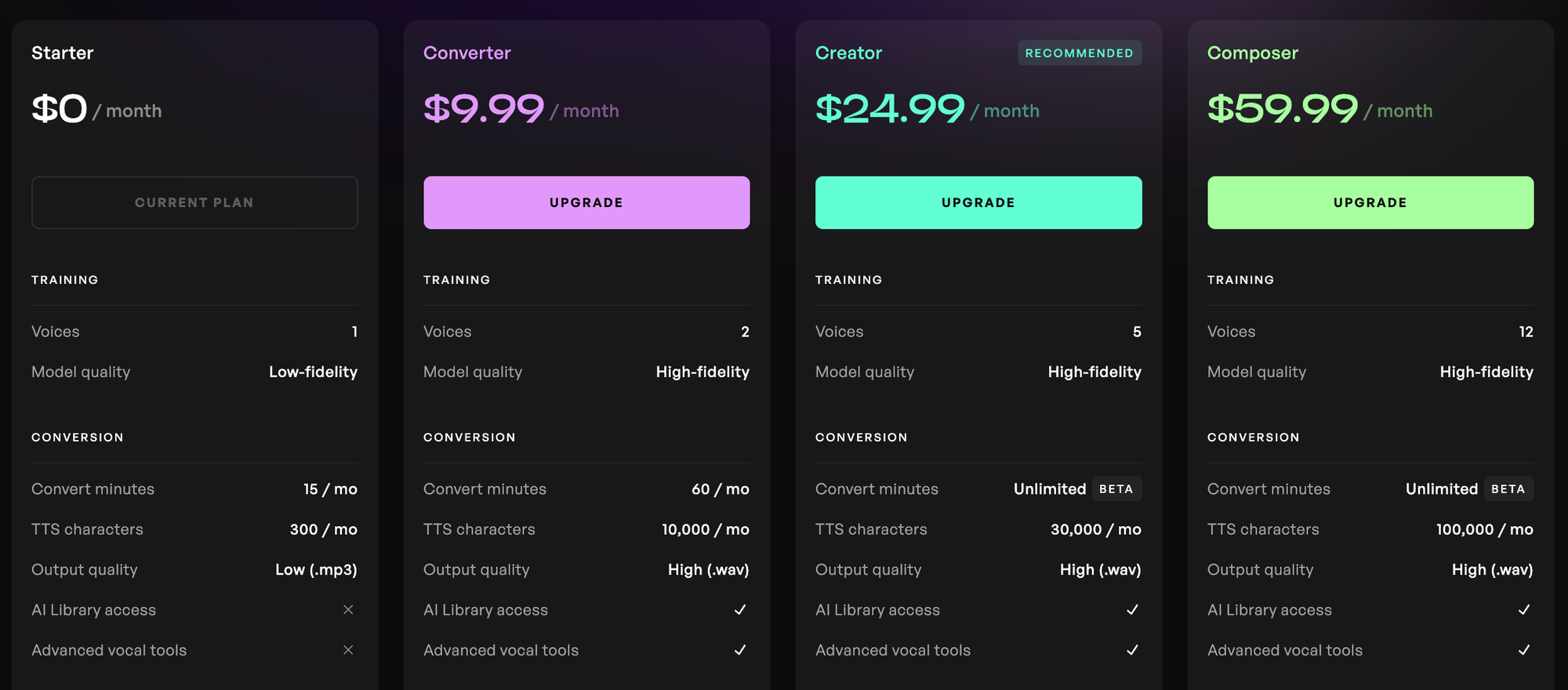
Tienes que entrar a Kits.ai y hacerte una cuenta.
La cuenta gratuita debería bastar para crear tu primera voz.
Entrenando la voz
Una vez en la plataforma deberás ir a Convert > Train >Train a voice y elige el tipo de entrenamiento. Si es que estás usando al cuenta gratuita sólo tendrás el modo Starter.
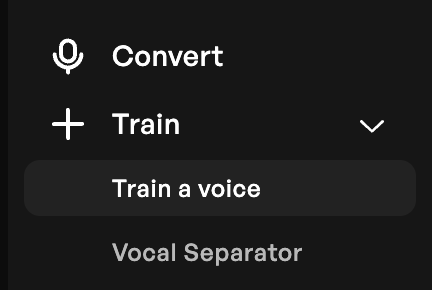
En la siguiente pantalla te pedirá subir tus archivos de audio que deben haber sido procesados como te expliqué en la sección anterior.
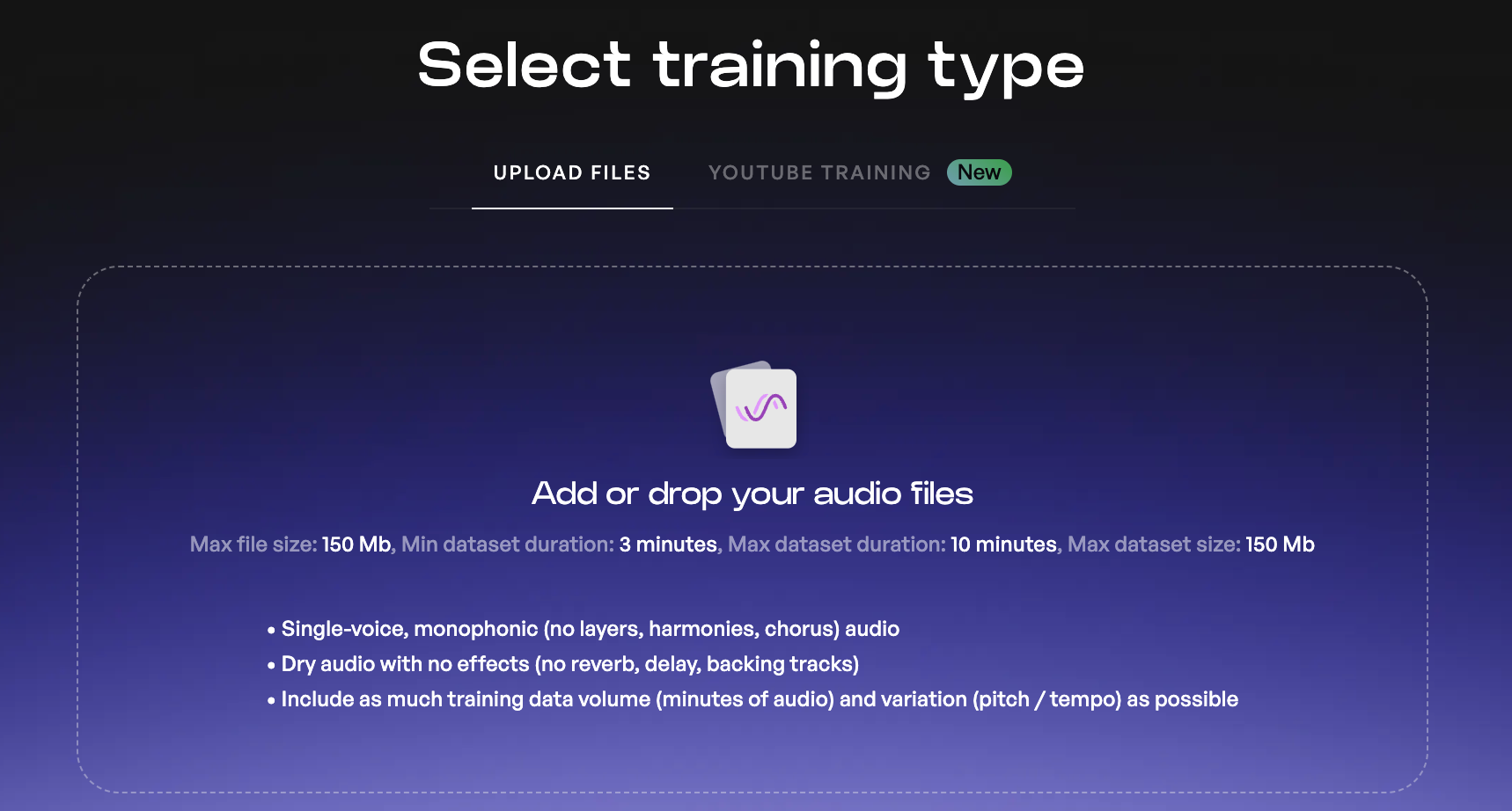
Ten en consideración que no podrás re-entrenar la voz con más audios después, así que te recomiendo trabajar todos los audios necesarios antes de este paso.
En la siguiente parte deberás darle un nombre a tu voz, y clasificarla en tipo e idioma.
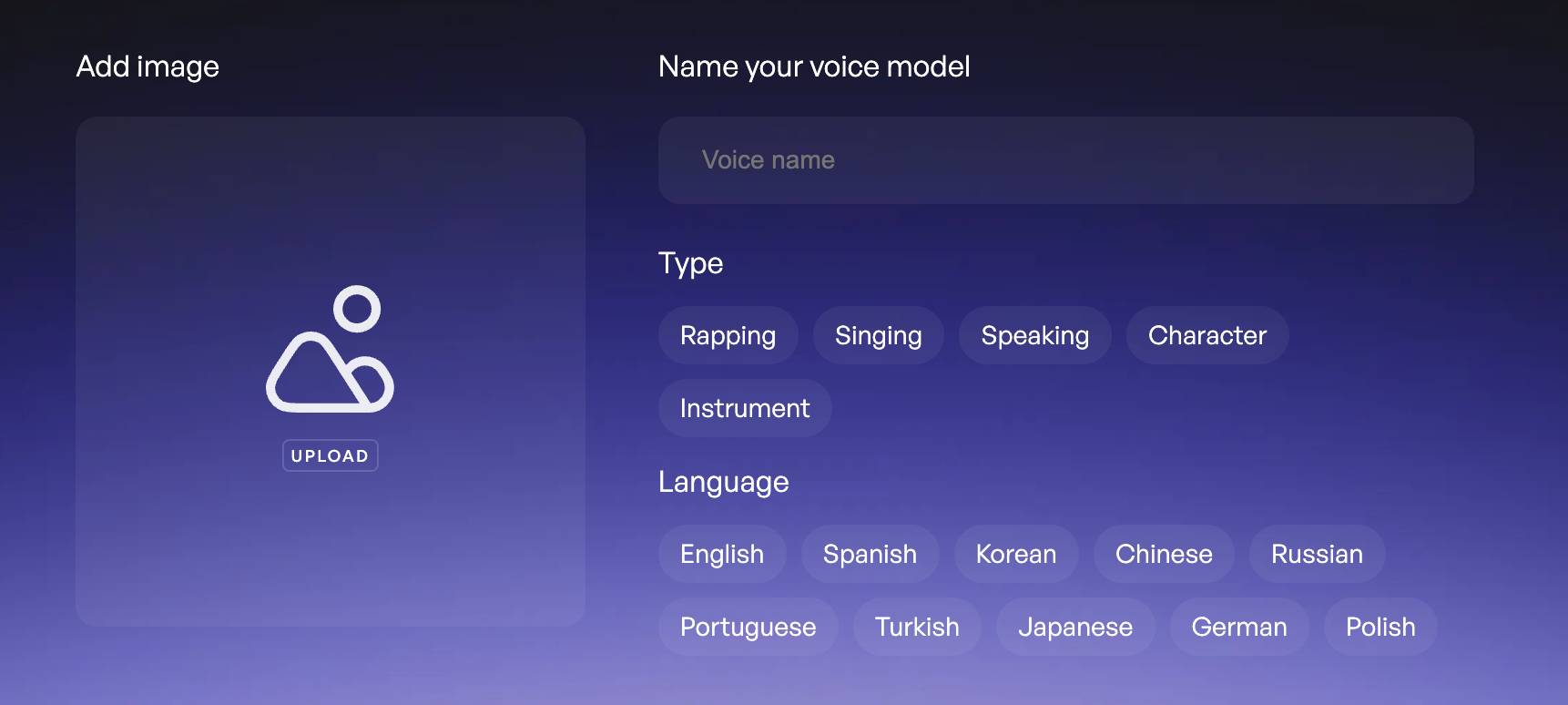
Una vez que hayas hecho esto el modelo comenzará a aprender tu voz. La plataforma te dará un tiempo estimado, pero en mi experiencia este tiempo siempre es menor, aunque no menos de 30 minutos. Puedes cerrar el sitio web en este paso.
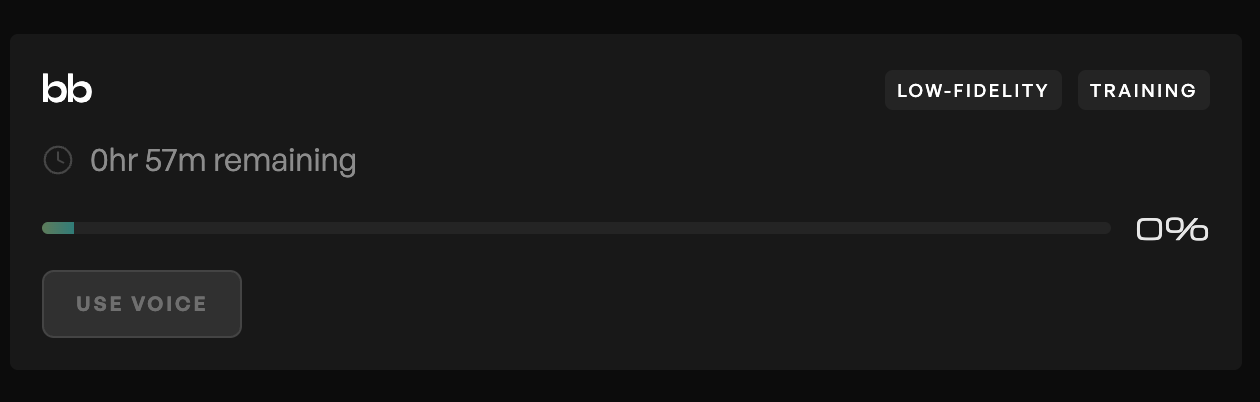
Cuando la voz termine de entrenarse vas a recibir un mail notificando de que tu voz ya está lista para ser usada.

Utilizando tu voz
Una vez que tu voz esté lista podrás entrar al siguiente panel.
Aquí podrás subir un archivo directamente a través de la opción "add or drop file" o bien grabarlo con el micrófono de tu computador con la opción "record". Asegúrate de tu audio sea sólo tu voz. Si necesitas añadir elementos como ruido de fondo, u otros, hazlo posteriormente.
Una vez que ya hayas subido el audio a convertir presiona "Convert" y espera el resultado.
Tus resultados se van a guardar en la página de la voz, por lo que podrás volver a buscarlos y no necesitas descargarlos inmediatamente. Sin embargo lo que tú envíes no siempre se guarda.
En la versión gratuita de Kits AI tendrás 15 minutos para generar, lo cual se renueva todos los meses. Esto es mucho más que otros servicios comparables.
Resultados
Estos fueron mis resultados con las distintas voces. Creo que son buenos resultados, pero se pueden mejorar. Hablaremos más de eso en la siguiente sección.
Voz de Bad Bunny
Esto fue lo que yo subí
Esto fue lo que generó
Voz de Ronaldo
Esto fue lo que yo subí
Esto fue lo que generó
¿Cómo mejorar los resultados?
En este tutorial vimos un ejemplo sencillo y rápido de hacer, pero estos resultados son mejorables con estos pasos
Adquirir una mejor licencia
Para este tutorial utilizamos la versión gratuita de Kits AI, sin embargo la versión premium tiene acceso a modelos con más precisión
Darle más y mejores audios de entrenamiento
Para este tutorial utilizamos audios de solo dos canciones. En tu caso puedes darle más canciones, y que sean más representativas del estilo del artista.
En el caso de la voz de CR7 noté mucha diferencia cuando se entrenaba el modelo con entrevistas recientes del futbolista. Cristiano ha mejorado mucho su acento en los últimos años, por lo que las entrevistas más antiguas eran más representativas de lo que los audios de TikTok hacen.
Mejorar tu entonación y pronunciación
En la versión original de NostalgIA también "canta" Justin Bieber, pero lo hace en español. El productor de FlowGPT declaró que él no pudo hacer esta canción en inglés pues él mismo no podía cantar en inglés. Para solucionarlo, otro productor peruano escuchó como Justin Bieber pronuncia y generó ese audio.
De modo similar, probablemente encontraste mis audios de Bad Bunny poco naturales. Esto es porque yo desconozco como él pronuncia. Lo único que sé de él y de su música es que luchó en la WWE. Así que es probable que un verdadero fan sí pueda imitar lo más característico de su manera de hablar.
Consideraciones
En este artículo hemos querido explicarte como se hacen este tipo de cosas con fines educativos, y por ello no te entregamos los audios de entrenamiento ni las voces ya entrenadas, pero si quieres utilizar la voz de una persona para distintos fines debes obtener su consentimiento.
Además no debes utilizar ninguna voz para fines distintos a los que te hayan autorizado.
