
Así es como hicimos a ChatGPT responder la PAES
En este post te explicamos el código y los pasos que seguimos para pedirle a ChatGPT de OpenAI que resolviera las pruebas PAES de Chile. Te invitamos a replicar nuestros experimentos y a contribuir con nuestro repositorio en Github!


por Jonathan Vásquez | linkedin | gscholar
En el artículo "ChatGPT supera al 99% de los estudiantes en la PAES" mostramos los resultados de nuestros experimentos con ChatGPT respondiendo las pruebas de Comprensión Lectora e Historia y Ciencias Sociales de la PAES. Y tal como lo habíamos anunciado, en pro de la transparencia y replicabilidad, en este link publicamos el repositorio con el código de nuestro experimento. Además, explicaremos en este artículo la estructura del proyecto y algunas partes del código que encontrarás en el reposotorio.
Te invitamos a estar atento a las actualizaciones del repositorio usando el botón watch, como también a clonarlo en tu computadora y replicar los resultados siguiendo las explicaciones de más abajo. Si te sientes con suerte, puedes ir directo al repositorio y explorar por tu propia cuenta el código. O si prefieres, te recomendamos usar CodeGPT para generar explicaciones directas desde el código.
También puedes contribuir abriendo pull requests, haciéndonos saber algún problema levantando issues, o usar nuestro formulario de Contacto para contactarnos con cualquier inquietud que tengas.
Y sin más preámbulo, comenzamos con la explicación del proyecto ¡Esperamos que sea de tu agrado!
Este post es un poco más técnico que los anteriores, pues estamos explicando código que usamos para hacer que ChatGPT responda la PAES. Pero no te preocupes, lo hemos escrito de forma clara y sencilla para que puedas seguirlo sin problemas. Además, creemos que puede ser una buena oportunidad para que comiences a meterte en este mundo de las APIs para usar los potentes modelos detrás de las inteligencias artificiales. Verás que no es tan difícil como parece y que puedes hacer cosas increíbles con solo unas líneas de código. ¡Anímate a probarlo y comparte tus resultados con nosotros!
Estructura del Proyecto
Escribiendo el Código
Para nuestros experimientos usamos Python. Además, instalamos los paquetes que aparecen en requirements.txt, incluyendo los Python bindings de OpenAI. Si aún no lo haces, te invitamos a seguir estos pasos que OpenAI señala en su página web y a instalar los paquetes usando los pasos señalados aquí.
El proyecto se divide en dos partes: Pre-procesamiento y PAES. El primero se enfoca en procesar los archivos PDF de las pruebas PAES que el DEMRE publica en su página web, mientras que el segundo usa la API de OpenAI para que GPT3.5 y GPT4 respondan a las pruebas procesadas.
Pre-procesamiento
Los archivos PDF fueron procesados y transformados a texto plano .txt para facilitar su uso en la siguiente etapa. Para lograrlo programamos dos pasos: (1) extracción y etiquetado, y (2) depurado.
(1) Extracción y Etiquetado
En la extracción del texto de las pruebas PAES usamos , que permite crear un objeto con información estructurada de los archivos PDF. En nuestro caso utilizamos la propiedad pages para iterar en la lista de páginas y el método extract_text() para recuperar las líneas de texto que contenían las preguntas y las alternativas. Para iterar únicamente en las paginas que solo contenían preguntas, creamos los argumentos start_questions y end_questions, los cuales indican el número de la página de inicial y final de las preguntas y alternativas. Estos son entregados al momento de ejecutar el archivo prepare_pdf.py (más adelante entregamos más detalle sobre este).
Luego etiquetamos cada línea según patrones distintos que identificamos al analizar el texto extraído. En particular, nos interesaba saber qué líneas contenían las preguntas y las alternativas y, así, obviar aquellos textos que eran inútiles para nuestro objetivo. Una lista de las distintas etiquetas y las condiciones para asignarlas se puede encontrar en la función define_label del archivo utils.py. La Figura 1a muestra un extracto de líneas de texto que se obtienen con extract_text() de una de las pruebas PAES y la Figura 1b expone cuál es el resultado después del etiquetado.
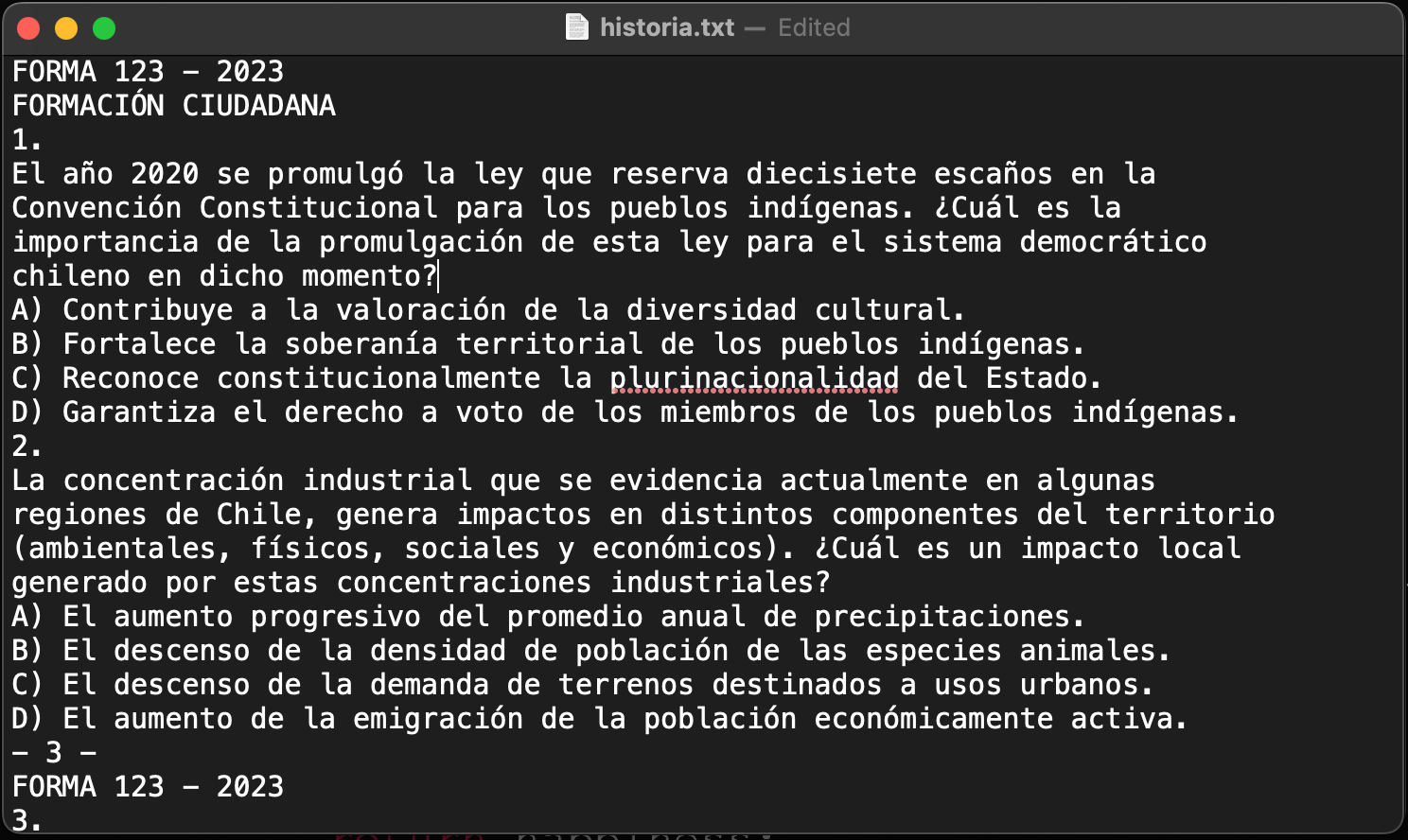
extract_text().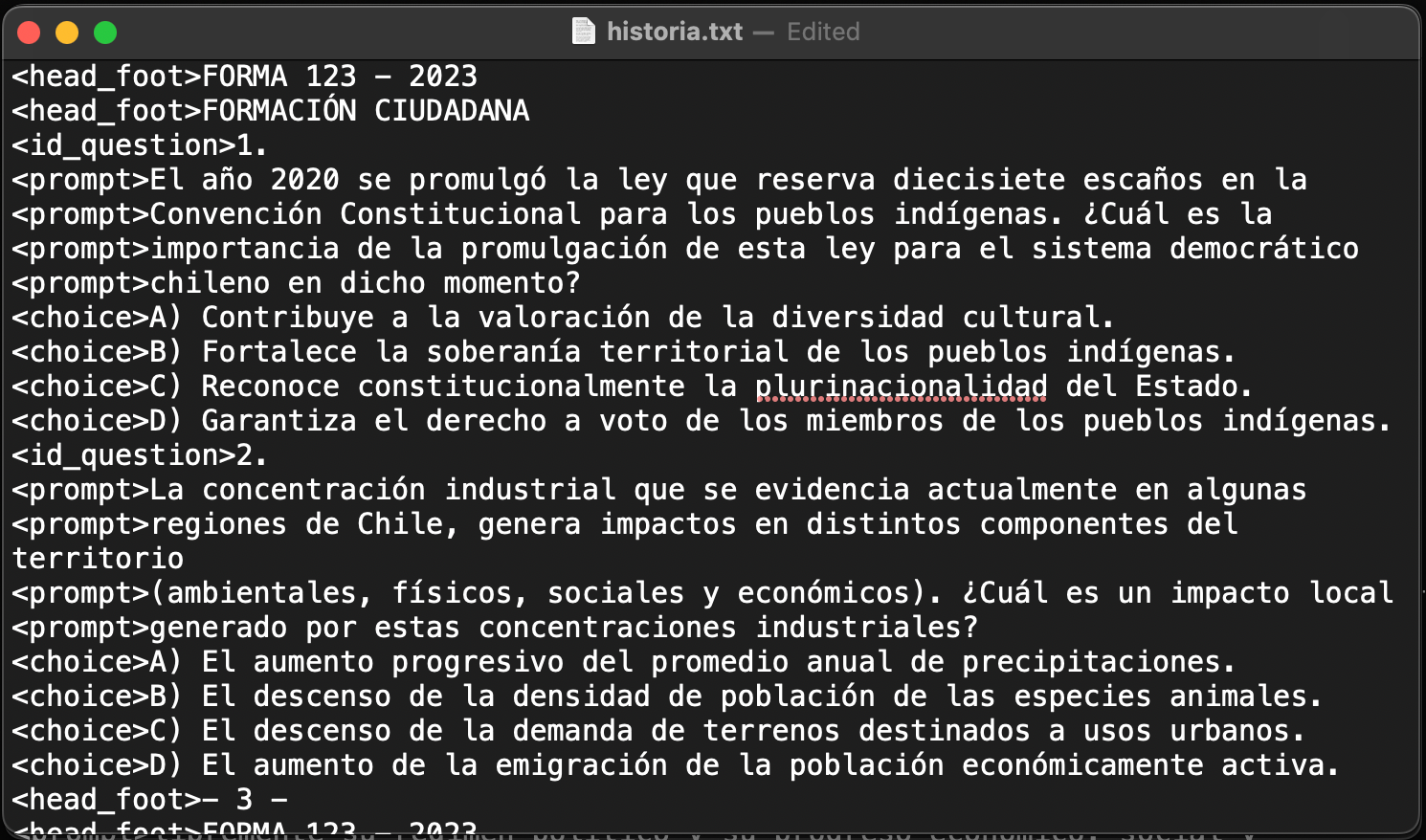
El proceso anterior lo pueden encontrar en la función label_pdf(args.in_path) donde args.in_path es el directorio en el que se ubica el ensayo en PDF.
def label_pdf(args):
labels = []
splitted_text = []
pdf = pdfplumber.open(args.in_path)
for pages in pdf.pages[args.start_questions-1:(args.end_questions)]:
text = pages.extract_text()
for line in text.split('\n'):
if re.match(r'^–.*–$', line) or re.match(r'-.*-$', line) or re.match(r'FORMA.*', line):
if len(labels)>0 and (labels[-1]=='<head_reading>' or labels[-1]=='<reading>'):
continue
define_label(line, labels)
splitted_text.append(line)
with open(args.out_path, 'w') as f:
f.writelines([label+text+'\n' for label,text in zip(labels, splitted_text)])(2) Depurado
Si bien el proceso de etiquetado permite reducir bastante tiempo en la identificación de la información útil, a veces hay ciertos patrones que no son identificados en la función define_label y generan etiquetados incorrectos. Para solucionar este problema creamos la función fix_labels, que recorre el texto etiquetado, identifica los errores y los vuelve a etiquetar. Eventualmente este proceso requiera ser complementado con algún ajuste natural. Según nuestra experiencia, este ajuste fue necesario solo en uno de los textos.
Finalmente, con el fin de entregarle a ChatGPT solo información relevante, creamos un proceso que elimina todas las líneas que contienen información inútil (como el número de página y el número de la forma). Para esto, construimos una función que, habiendo recibido un texto etiquetado, lo recorre y borra las líneas con las etiquetas <head_foot> y <other>. Este proceso lo programamos en la función only_questions().
def only_questions(args):
with open(args.in_path, 'r') as f:
text = f.readlines()
final_text = []
labels = []
for line in text:
parts = line.split ('>')
if len(parts) == 2:
l = parts[0]+'>'
txt = parts[1].strip()
final_text.append(txt)
labels.append(l)
if args.only_questions:
final_text = [text
for text, label in zip(final_text, labels)
if not(label=='<other>' or label=='<head_foot>')]
labels = filter(lambda x: not(x=='<other>' or x=='<head_foot>'), labels)
with open(args.out_path, 'w') as f:
f.writelines([label+text+'\n' for label,text in zip(labels, final_text)])La Figura 2 muestra un texto listo para ser utilizado en la siguiente etapa. Te puedes fijar que ya no están algunas líneas que sí aparecía en la Figura 1b, tales como las que contenían el texto FORMA 103 - 2023 y FORMACIÓN CIUDADANA.
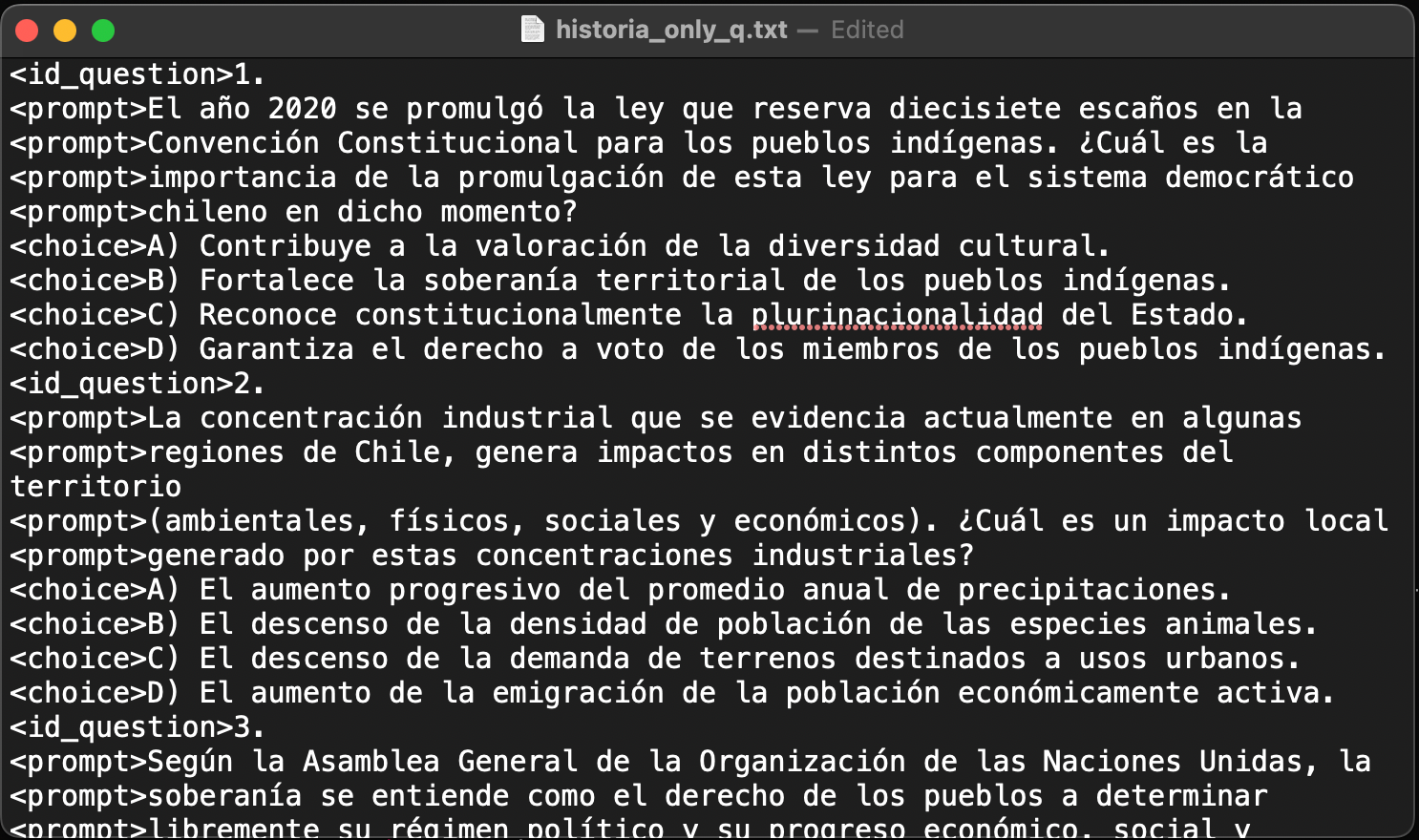
PAES
En esta segunda etapa usamos las pruebas PAES procesadas en la etapa anterior y le pedimos a ChatGPT que respondiese las pruebas por medio de la API de OpenAI.
Según la documentación de OpenAI, primero necesitas generar una API KEY siguiendo los pasos publicados por OpenAI. Una vez que la obtengas, deberás guardarla en el archivo key.txt, reemplazando el texto PASTE_HERE_YOUR_API_KEY por la llave que generes en OpenAI.
Es fundamental este paso; sin una API KEY no podrás correr los experimentos. También debes considerar que esto implica un pago por la cantidad de tokens que utilices. Nosotros hicimos varios llamados a la API durante el desarrollo de los experimentos y en total pagamos menos de 5,00 dólares. Pero en tu caso podría ser mucho menos. Para tener una referencia, el costo total de responder la PAES de Historia y Ciencias Sociales del proceso regular admisión 2023 usando GPT4 y GPT3.5 fue de 0,13 dólares.
Para responder la PAES, hacemos llamados a la API usando los modelos basados tipo chat. Estos modelos pueden tomar una serie de mensajes de entrada y retornar una respuesta. Adicionalmente, se pueden configurar varios parámetros, tales como el temperature y top_p, que varían la aleatoriedad de la respuesta.
En nuestro caso, solamente modificamos los argumentos model y messages, usando los valores por defecto en los demás parámetros. Para model usamos los ID gpt-3.5-turbo (modelo GPT3.5) y gpt-4 (modelo GPT4), mientras que para messages seguimos la siguiente estructura:
messages=[{"role": "system", "content": system_content},
{"role": "user", "content": user_content}]Donde system_content corresponde al prompt de contexto y user_content a la lista de preguntas y alternativas. La plantilla que sigue system_content ya la explicamos en el artículo anterior y se encuentra guardada en el archivo system.txt.
Todo el proceso anterior está programado en la siguiente función:
def obtain_answer(system_content, user_content, key_path, model):
with open(key_path, 'r') as f:
key = f.read()
openai.api_key = key
response = openai.ChatCompletion.create(
model=model,
messages=[{"role": "system", "content": system_content},
{"role": "user", "content": user_content}]
)
return responseLímite de tokens
Los modelos GPT3.5 y GPT4 aceptan un máximo de tokens que limita la cantidad de texto que podemos enviar y recibir en la llamada de la API. Aunque GPT4 tiene un límite mucho mayor, asignamos para ambos modelos el mismo umbral de 4.096 tokens, que es igual al máximo para GPT3.5.
El problema es que este límite permite un largo de texto que es menor al de toda una prueba PAES, por lo que para poder entregarle todas las preguntas, generamos un proceso iterativo en el que las preguntas y alternativas se van anexando al user_content de tal manera que no se supere el máximo de tokens. En el momento en que llegamos al máximo, se llama a la API y se guardan las respuestas, y se vuelve a generar el user_content utilizando la misma lógica hasta que no haya más preguntas por responder.
Para el caso de la PAES de Comprensión Lectora agregamos una condición adicional para lograr que las preguntas que tenían asociadas lecturas, siempre incluyeran tanto la pregunta como la lectura en la misma consulta.
Todo este proceso lo podrán ver en detalle en el archivo paes.py en la carpeta src.
Experimentos
Obteniendo las respuestas a la PAES
Para ejecutar los experimentos creamos las interfaces prepare_pdf.py y answer_paes.py . El primero permite procesar los archivos PDF, mientras que el segundo utiliza los textos procesados para pedirle a ChatGPT responder las pruebas.
Veamos un ejemplo usando la PAES de Historia y Ciencias Sociales del proceso regular 2023.
Primero, descargamos la prueba desde el DEMRE y la guardamos en el siguiente directorio: ensayos/regular_2023/2023-22-11-30-paes-oficial-historia-p2023.pdf. Este archivo ya se encuentra en el proyecto, por tanto, no es necesario que vayas al DEMRE a descargarlo.
Luego, procesamos la prueba usando los siguientes tres comandos en el terminal:
python prepare_pdf.py --in_path ensayos/regular_2023/2023-22-11-30-paes-oficial-historia-p2023.pdf --out_path preprocessed/regular_2023/historia.txt --start_questions 3 --end_questions 47 --label --verbose
python prepare_pdf.py --in_path preprocessed/regular_2023/historia.txt --out_path preprocessed/regular_2023/historia_fixed.txt --fix --verbose
python prepare_pdf.py --in_path preprocessed/regular_2023/historia_fixed.txt --out_path preprocessed/regular_2023/historia_only_q.txt --only_questions --verboseEl resultado debe ser algo similar a lo que mostramos en la Figura 2. El que nosotros obtuvimos se puede encontrar en el archivo historya_only_q.txt guardado en la carpeta preprocessed/regular_2023.
Una vez procesada la prueba, usamos el archivo answer_paes.py para pedirle a ChatGPT que responda la PAES. Para GPT3.5 (que es el modelo gratuito), usamos el siguiente comando en la terminal:
python answer_paes.py --in_path preprocessed/regular_2023/historia_only_q.txt --out_path results/regular_2023/historia_gpt3.5.txt --model gpt-3.5-turbo --verboseEsto generará un archivo de texto plano historia_gpt3.5.txt en la carpeta results/regular_2023, el cual contendrá una lista con los números de cada pregunta y la respuesta que el modelo contestó.
El archivo se debería ver así:
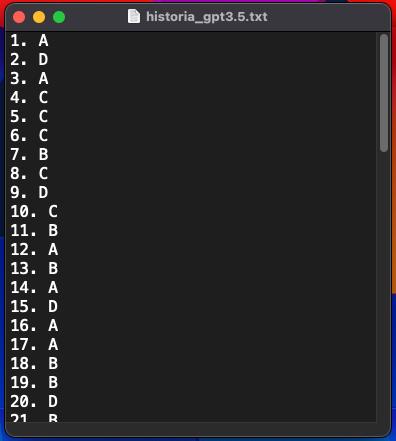
¡Hemos terminado! Ahora podemos usar este texto y comparar las respuestas con el clavijero que entrega el DEMRE y seguir los pasos que ahí se mencionan para calcular el puntaje PAES que obtendría ChatGPT.
En el caso de que tengas acceso a la API, en la carpeta prompts dejamos archivos .txt para que copies y pegues directo a ChatGPT. Para que no tengas problemas con el límite de tokens, separamos cada prueba en pedazos de textos con los caracteres -----, tal como lo muestra la siguiente figura.

Hemos llegado al final de este post ¡Esperemos que haya sido de tu agrado! Recuerda que ante cualquier duda puedes contactarnos en este formulario, o abrir un nuevo issue en el repositorio que subimos a Github. También puedes hacer un nuevo pull request para contribuir al repositorio.
Es importante recalcar que tus resultados pueden variar un poco respecto de de los que nosotros mostramos en la carpeta results, ya que usamos los parámetros por defecto de temperature y top_p, los cuales agregan un grado de aleatoriedad.
¡Coméntanos como te fue y suscríbete para recibir notificaciones de los futuros posts!