
ChatGPT Vuelve a Responder la PAES: ¿Empeoró o mejoró en el tiempo?
Estudios indican que ChatGPT está empeorando en desempeño. Quisimos ponerlo a prueba pidiéndole que vuelva a responder la PAES. Además le pedimos que responda la reciente versión Invierno Admisión 2024. Sigue leyendo y sorpréndete con los resultados.


En abril del presente año, llevamos a cabo un experimento en el que le pedimos a ChatGPT que respondiera las preguntas de la PAES del Proceso de Admisión 2023. Los resultados resonaron en diversos medios de comunicación nacionales y generaron una amplia discusión en redes sociales y motivaron el envío de cartas al editor de periódicos.
Desde entonces, diversos investigadores y organizaciones han evaluado la habilidad de ChatGPT para responder a diferentes tipos de pruebas. Este ejercicio fue iniciado por la misma empresa que desarrolló ChatGPT: OpenAI, quien publicó un artículo demostrando la eficacia de sus modelos GPT3.5 y GPT4 para responder a pruebas estandarizadas, como el SAT y el GRE, que se utilizan en el proceso de admisión a programas de pregrado y posgrado en universidades.
Uno de los estudios que más capturó nuestra atención –y que hemos comentado en nuestro podcast ¿Qué IA está pasando? y que puedes escuchar en nuestras redes sociales– fue el realizado por investigadores de Stanford y UC Berkeley, en el que indican que ambos modelos, GPT3.5 y GPT4, exhiben variaciones significativas entre marzo y junio de este año.
Inspirados por estos hallazgos, decidimos implementar una evaluación similar con ChatGPT en la tarea de responder la PAES. Contrastamos los resultados obtenidos en abril con aquellos recopilados al repetir los experimentos. Además, aprovechamos la reciente publicación del DEMRE de la PAES Invierno Admisión 2024 para preguntarle a ChatGPT que responda a las pruebas de Historia y Ciencias Sociales, así como a la de Competencia Lectora. Posteriormente, comparamos su rendimiento con los resultados de la PAES Invierno Admisión 2023.
¿Ha experimentado ChatGPT un deterioro en su desempeño a lo largo del tiempo en la resolución de la PAES? ¿Se ha mantenido, ampliado o reducido la diferencia entre la versión pagada de GPT4 y su contraparte gratuita, GPT3.5? ¿Podrá ChatGPT repetir su exitoso rendimiento en la próxima PAES de Invierno, al igual que lo hizo en la PAES Regular del año anterior? ¡Exploramos estas preguntas y más en este post!
En pro de la transparencia y replicabilidad, todo el codigo de los experimentos puede ser encontrado en este repositorio.
También puedes revisar el post donde explicamos el proyecto completo.
Principales Hallazgos
- La versión GPT3.5 de ChatGPT muestra una reducción en el rendimiento en la tarea de responder la PAES de Competencia Lectora en comparación con el estudio realizado en abril, mientras que la versión GPT4 mantiene una estabilidad más constante en su desempeño para la misma prueba.
- Por otro lado, en la prueba de Historia y Ciencias Sociales, ChatGPT con GPT4 logra responder correctamente todas las preguntas de la PAES Regular del 2023 en los nuevos experimentos, igualando o superando al 100% de los postulantes.
- En la PAES Invierno de Admisión 2024, ChatGPT con GPT4 muestra mejores resultados que con GPT3.5, hallazgo también observado con las pruebas del Proceso de Admisión 2023.
- Comparando los desempeños de ambas pruebas en estudio de la PAES Invierno de Admisión 2024, ChatGPT logra mejores puntajes en la de Competencia Lectora, pero muestra una baja significativa en la de Historia y Ciencias Sociales, mientras que para las versiones de Admisión 2023, observamos lo contrario: ChatGPT obtiene peores puntajes en Competencia Lectora que Historia y Ciencias Sociales.
ChatGPT de Abril vs Agosto 2023
variación en el desempeño a lo largo del tiempo
La respuesta concisa es que sí, el rendimiento de ChatGPT ha variado en comparación con lo observado en abril (Ver Figura 1). Sin embargo, a diferencia de otros estudios, creemos que dicha variación no es significativa. Por un lado, GPT3.5 demostró una disminución en la precisión en comparación con abril en la PAES de Competencia Lectora; en cambio, GPT4 no mostró ninguna variación en el número de respuestas correctas. En cuanto a la prueba de Historia y Ciencias Sociales, ambos modelos mostraron mejoras generales, con GPT4 logrando responder acertadamente a todas las preguntas de la PAES Regular realizada en noviembre del año anterior.
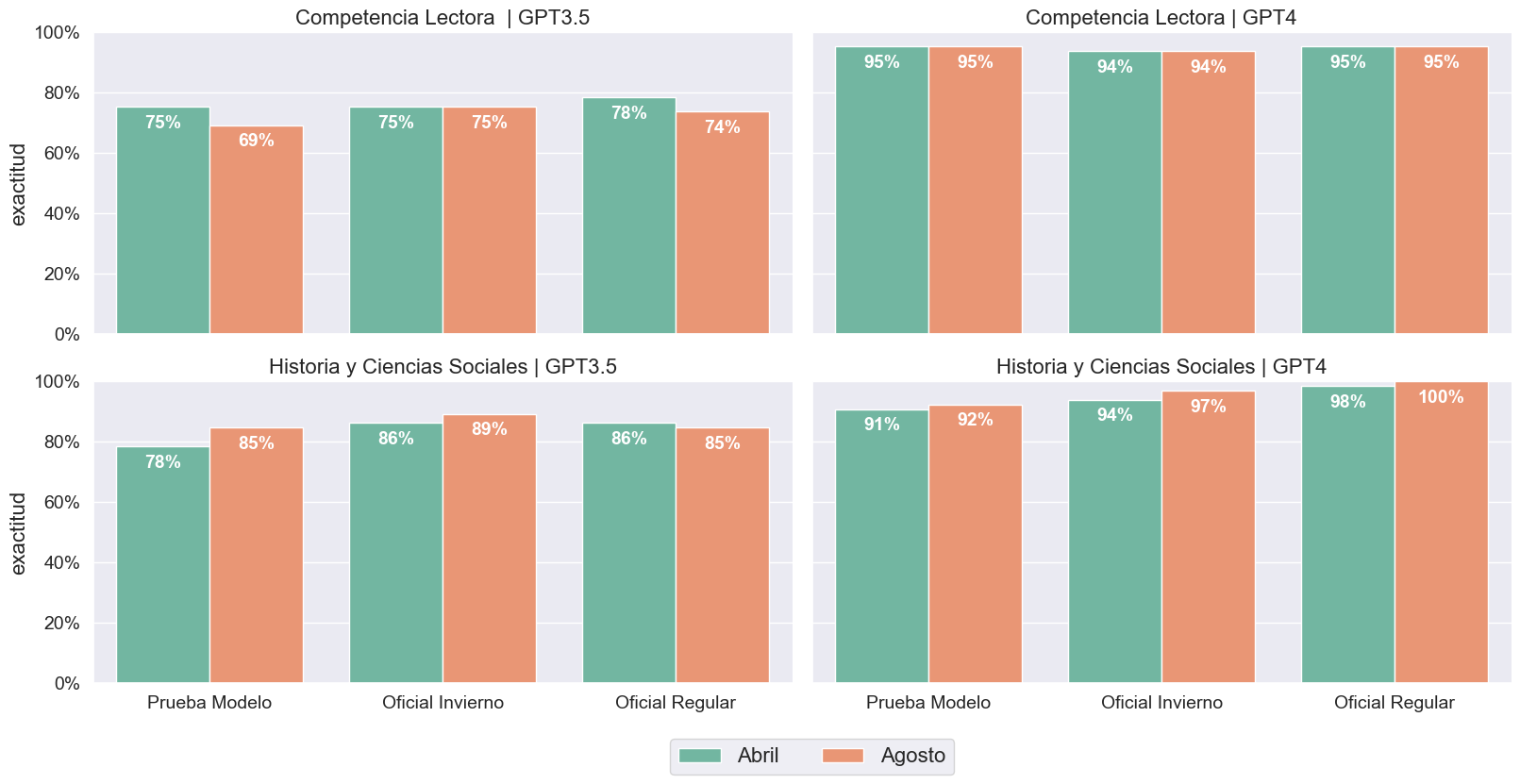
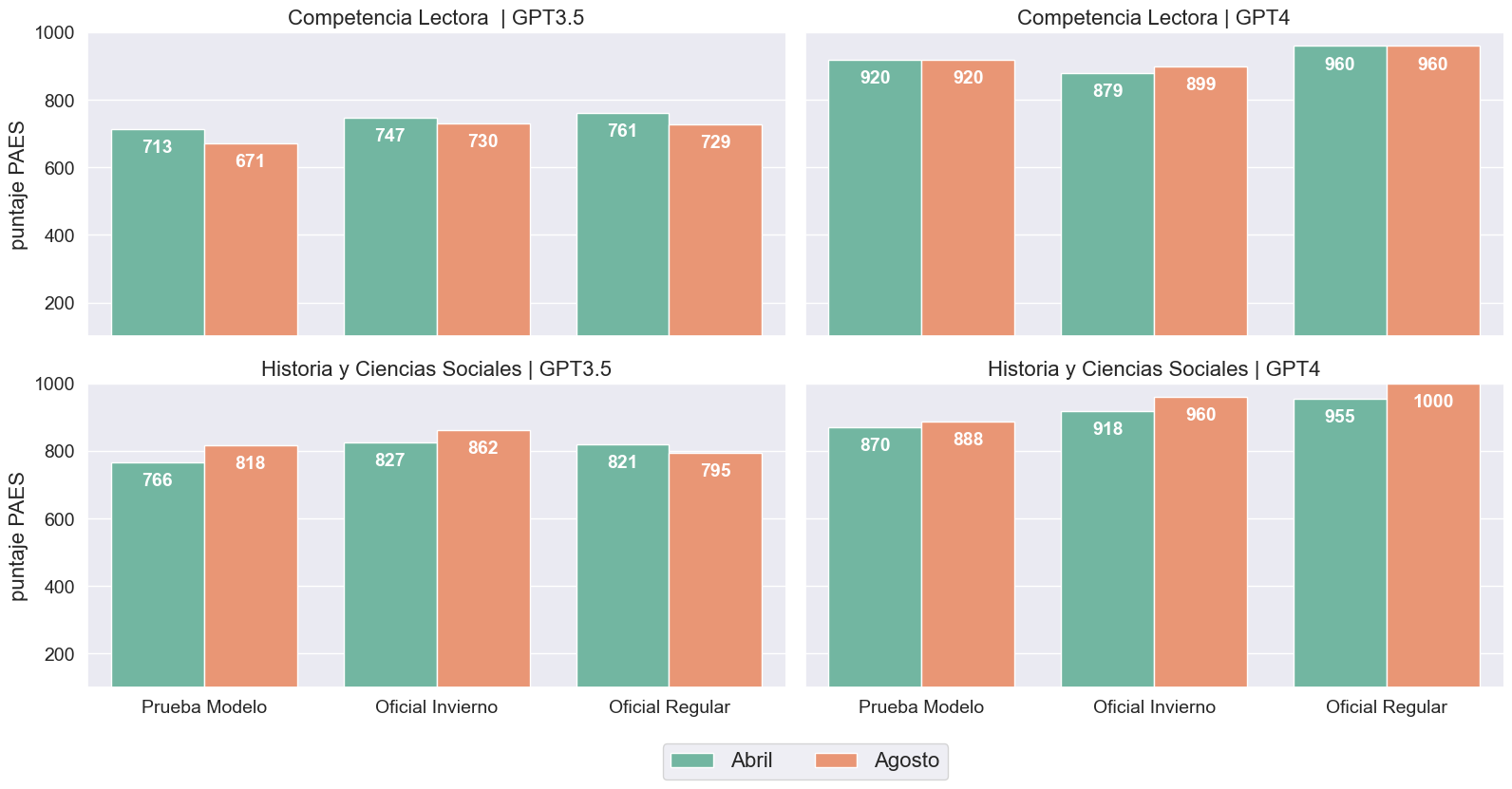
Observamos un fenómeno similar al calcular los puntajes PAES. Cabe recordar que, según los clavijeros oficiales publicados por DEMRE, solo se utilizan 60 de las 65 preguntas para calcular el puntaje. Dicho esto, según Figura 2, GPT3.5 mostró una disminución en el rendimiento en las tres versiones de Comprensión Lectora, incrementando de 1 a 4 las respuestas incorrectas. Esta disminución se traduce en una pérdida de entre 17 y 95 puntos en comparación con los experimentos realizados en abril. En contraste, GPT4, la versión de pago, mostró cambios mínimos; de hecho, solo aumentó 20 puntos en la PAES de Invierno, lo que se atribuye a que, a diferencia de abril, tuvo una respuesta correcta adicional (pregunta número 25).
En cuanto a la prueba de Historia y Ciencias Sociales, hemos notado variaciones más significativas. Cuando publicamos el estudio en abril, lo que causó mayor revuelo fue que ChatGPT, utilizando GPT4, superó al 99% de los estudiantes que tomaron la PAES en noviembre de 2022. Al solicitarle que vuelva a responder esta prueba ahora, ChatGPT logra un puntaje perfecto, superando a la mayoría e igualando a aquellos que también obtuvieron 1.000 puntos. Por otro lado, al pedirle a ChatGPT que responda la prueba con GPT3.5, también vemos una mejora en el puntaje en las tres versiones, evidenciando un aumento de 52 puntos con la versión Modelo de la PAES. No obstante, en el caso de la versión Regular, observamos una disminución en el puntaje, de 821 a 795 puntos.
PAES Invierno Admisión 2024
y comparación con proceso de Admisión 2023.
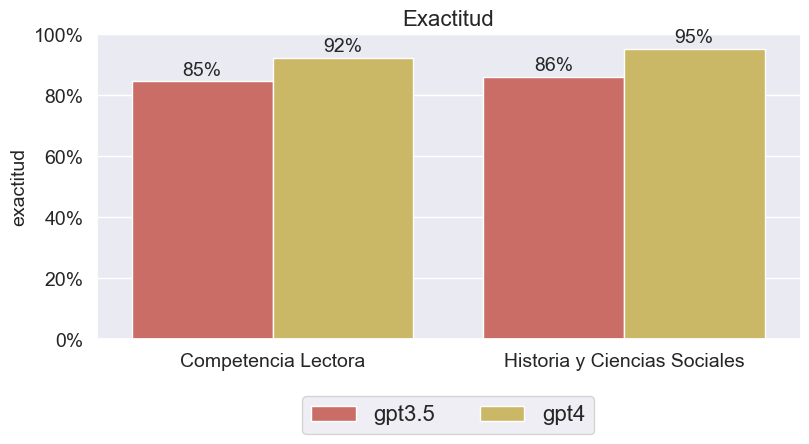
En general, de acuerdo a las Figuras 3 y 4, GPT4 supera a GPT3.5 en la prueba PAES Invierno de este año. Cuando se trata de exactitud, ambos modelos exhibieron un alto rendimiento en ambas pruebas. En el caso de Historia y Ciencias Sociales, los resultados fueron de 62 y 56 respuestas correctas para GPT4 y GPT3.5, respectivamente; mientras que en Competencia Lectora fue de 55 y 60. Este patrón es similar a los resultados observados en la prueba de Invierno de Admisión 2023, donde ChatGPT mostró rendimientos en exactitud mejores con Historia y Ciencias Sociales.
Además, nos gustaría destacar que la discrepancia en exactitud entre los modelos GPT3.5 y GPT4 durante la prueba de Competencia Lectora Invierno Admisión 2024 es menor que en las pruebas de invierno del año anterior. En la prueba de Invierno Admisión 2023, hubo una brecha de 19 puntos porcentuales entre los dos modelos, mientras que en la prueba de Invierno Admisión 2024, esta brecha se redujo a solo 7 puntos porcentuales.
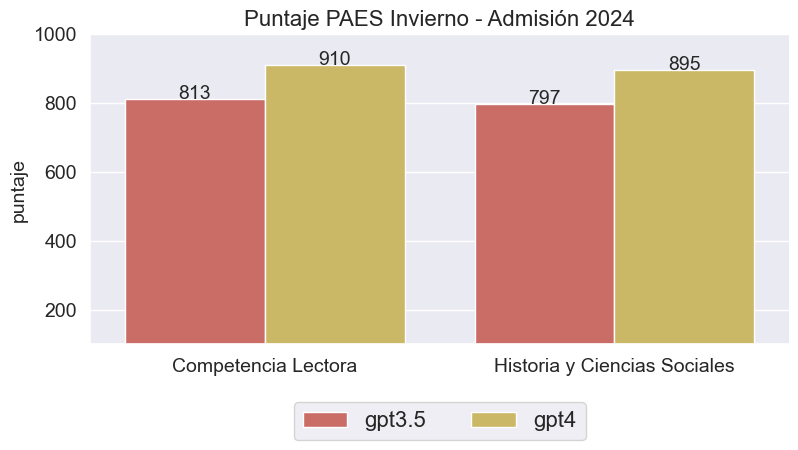
En relación con los puntajes PAES, de acuerdo con el clavijero oficial publicado por el DEMRE, ChatGPT demuestra un rendimiento superior en la prueba de Competencia Lectora en comparación con la de Historia y Ciencias Sociales (ver Figura 4). Este hecho resulta intrigante, dado que la tendencia en las pruebas del año anterior fue inversa. Será interesante verificar si este nuevo hallazgo persiste en la versión regular que se llevará a cabo a finales del año en curso.
Según la información publicada por el DEMRE, el año pasado se introdujo un cambio en la metodología para calcular los puntajes. reemplazando la normalización a través del método de Rasch con un cálculo basado en el promedio de habilidades. De acuerdo con el DEMRE, este enfoque eliminaría la distorsión causada por la normalización y permitiría la comparación entre diferentes pruebas. Así, según señala DEMRE, cada estudiante tendría la posibilidad de combinar los puntajes de varias pruebas, dando lugar a un proceso más justo, flexible y preciso.
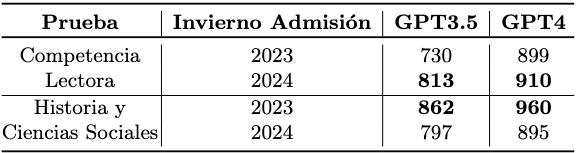
Dicho esto, decidimos comparar los puntajes obtenidos por ChatGPT en las PAES de Invierno para Admisión 2023 y 2024. Según los resultados de la Tabla 1, ChatGPT mostró una mejora en Competencia Lectora, aunque disminuyó su rendimiento en Historia y Ciencias Sociales, independientemente del modelo utilizado. Con el modelo GPT3.5, ChatGPT mejoró en 83 puntos en Competencia Lectora, pero descendió 65 puntos en Historia y Ciencias Sociales. Mientras, con el modelo GPT4, ChatGPT mejoró 11 puntos y también registró una disminución de 65 puntos en Historia y Ciencias Sociales.
Conclusiones
Como hemos observado en estudios anteriores, ChatGPT ha demostrado variaciones significativas a lo largo del tiempo en su rendimiento al responder pruebas estandarizadas. Tales hallazgos plantean una preocupación crucial, dado que dichos modelos se están integrando en diversos flujos de trabajo. De confirmarse tal variación, representaría un desafío considerable en términos de la estabilidad de cualquier aplicación que se base en estos modelos. Sin embargo, a diferencia de estos estudios, nuestros experimentos no han evidenciado tales fluctuaciones de relevancia. Este hecho podría interpretarse de manera positiva, ya que podría sugerir una estabilidad para las aplicaciones que utilizan GPT3.5 o GPT4 en el marco de la PAES. No obstante, no descartamos que pueda suceder en el futuro, por lo que se aconseja un seguimiento constante de posibles variaciones en el desempeño.
A pesar de lo expuesto en este artículo, consideramos necesario llevar a cabo un estudio más exhaustivo. En este, por ejemplo, se podrían analizar las diferencias a nivel de tipo de preguntas y aportar diversas perspectivas al fenómeno que examinamos en nuestros experimentos. Confiamos en que los hallazgos presentados aquí fomenten el interés en futuras investigaciones y de actores relevantes en el ámbito educativo chileno.
Siguiendo nuestra línea de experimentos iniciada en abril, creemos que es crucial reflexionar sobre los posibles efectos de la brecha entre los modelos GPT4 y GPT3.5. Esta disparidad en el rendimiento podría tener implicaciones si estas herramientas se incorporaran al sistema educativo, considerando además que GPT4 tiene un coste superior al de GPT3.5. Citando nuevamente a Kizilcec y Lee, debemos asegurarnos que el uso de este tipo de tecnología en educación generen un Closing Gap, y no que repliquen o aumenten las brechas. Por ende, invitamos a que futuras aplicaciones que usen estos modelos en la educación puedan afrontar con éxito este desafío. En nuestro caso, este contraste nos motiva a seguir monitoreando si esta brecha se ampliará en las futuras versiones de la PAES.
Finalmente, uno de los hallazgos más destacados en nuestros experimentos es la disminución del rendimiento de ChatGPT al responder la prueba de Historia y Ciencias Sociales en la PAES de Invierno para la Admisión 2024, en contraposición a la del 2023. Nos gustaría corroborar si este resultado se reitera en la versión Regular que se llevará a cabo a fin de año, lo que indicaría un cambio de tendencia respecto a las versiones para la Admisión 2023, donde ChatGPT responde mejor la prueba de Historia y Ciencias Sociales que la de Competencia Lectora.
Esperamos que te haya gustado este post! Coméntanos qué opinas más abajo o contáctanos aquí. No olvides suscribirte para recibir noticias de los futuros experimentos que iremos publicando.