
ChatGPT dio la PAES 2025: contesta perfectamente en una de las pruebas y entraría en medicina
ChatGPT rindió la PAES 2025. Probamos sus distintos modelos y los resultados fueron sorprendentes, llegando a tener 100% en una prueba.


En EvoAcademy hicimos que ChatGPT, con sus diversos modelos, contestara la PAES admisión regular 2025. Esta es la cuarta vez que hacemos el ejercicio. Anteriormente contestó la PAES Regular 2024, PAES Invierno 2024 y la PAES Regular 2023, y por primera vez logra obtener 100% de precisión en una de las pruebas.
Los modelos de lenguaje enormes, la tecnología detrás de ChatGPT y similares, se han ido sofisticando desde la primera vez que hicimos esta investigación. En esta ocasión hicimos que los modelos GPT-4o-mini, GPT-4o y los nuevos modelos de razonamiento o1 y o1-mini contestaran la prueba.
Principales resultados
- La IA logró obtener 100% de precisión en la prueba de Historía y Ciencias Sociales con 3 de los 4 modelos utilizados. Esta es la primera vez en nuestras evaluaciones que ChatGPT obtiene puntaje perfecto en una prueba.
- El desempeño mejora significativa en las pruebas de Ciencias la cual se distingue por sus preguntas enfocadas en observación y análisis de problemas. El promedio de las pruebas de Ciencias mejoró en 18% respecto a 2024, con un promedio del desempeño máximo de 909.25 (gpt-4o).
- gpt-4o no logra mejorar en las pruebas de Competencia Matemática, tanto M1 como M2, respecto a su antecesor. En la prueba 2024, gpt-4 logró 90% en M1 y 96% en M2. Por su parte, el desempeño máximo de gpt-4o en la prueba 2025 fue de 90% para M1 y 92% para M2. Esto está en línea con las evaluaciones de OpenAI, que muestran que el desempeño de GPT-4o es similar al de GPT-4 turbo.
- Los modelos de razonamiento o1 no son consistentemente mejores que los modelos GPT. A pesar de su mayor sofisticación, costo y tiempo de procesamiento, los nuevos modelos o1-preview y o1-mini no logran siempre mejores resultados que los modelos gpt-4o. Por ejemplo, en la prueba de Competencia Lectora, gpt-4o obtuvo un 93.33% de precisión máxima, mientras que los modelos o1 obtuvieron entre 86.67% y 93.33%.
- A pesar de que no fueron consistentemente mejores, el costo de procesamiento de los modelos o1 fue mucho mayor. Más detalles en la sección "Costos".
- Si fuese un estudiante, el modelo gpt-4o podría entrar a carreras como Medicina en la Universidad de Chile, Derecho en cualquier universidad, Ingeniería Plan Común en cualquier universidad, entre otras más. Esta es la primera vez que podría entrar a Medicina en una de las universidades con mayor puntaje de corte del país. Más detalles en la sección de Carreras.
Ve el detalle los resultados en esta sección.
Sobre la evaluación
La PAES, o Prueba de Acceso a la Educación Superior, es un test estandarizado que se utiliza como parte del sistema de admisión en gran parte de las universidades en Chile. Para esta evaluación utilizamos las pruebas oficiales publicadas por el Departamento de Evaluación, Medición y Registro Educacional (DEMRE) para el proceso de Admisión regular 2025. Estas son las mismas pruebas que los estudiantes rindieron el 2, 3 y 4 de diciembre de 2024.
Este año, el DEMRE decidió ser menos transparente que otros años, publicando aproximadamente el 70% de las preguntas de cada prueba. Las razones técnicas para este cambio se explican en este artículo, pero se puede resumir en que se necesitarían "reservar" preguntas para asegurar la integridad del instrumento.
Para poder otorgarle un puntaje al desempeño de ChatGPT, asumimos que las preguntas que se publicaron son representativas del resto de la prueba. A partir de esta muestra, aplicamos técnicas como el método de bootstrapping, y nos basamos en investigaciones recientes sobre evaluación de modelos para estimar el desempeño de ChatGPT en toda la prueba. Este procedimiento se repitió 1000 veces para cada configuración de los modelos, y el puntaje final se obtuvo promediando los resultados de todas las iteraciones.
Actualmente OpenAI, la empresa detrás de ChatGPT, ofrece distintos modelos, los cuales pusimos a prueba.
- gpt-4o, la versión más conocida de sus modelos. Este modelo puede ser utilizado gratuitamente en ChatGPT, pero con una cuota limitada, la cual es más holgada si pagas la suscripción mensual.
- gpt-4o-mini, la versión menos precisa, pero más rápida de sus modelos. Este modelo está siempre disponible en la versión gratuita de ChatGPT.
- o1 y o1-mini son los nuevos modelos de razonamiento de OpenAI. Son actualmente considerados como los mejores modelos de lenguaje, y alcanzan "niveles similares a un doctorado" en varias de las evaluaciones.
Debido a la sofisticación de los modelos, es razonable esperar que el orden de precisión sea (de menor a mayor): gpt-4o-mini, gpt-4o, o1-mini y o1 (preview). En las evaluaciones pasadas encontramos diferencias importantes, de casi 200 puntos, entre modelos, pero en esta edición los resultados no fueron tan dispares y tampoco siguieron el orden de precisión esperado.
Configuraciones de los modelos
Para los modelos GPT (gpt-4o y gpt-4o-mini) ejecutamos 12 versiones de los experimentos, combinando las siguientes posibilidades:
- Temperatura: 0, 0.3, y 0.6
- Capacidad de visión: activada, desactivada
- Chain-of-Though o Zero-shot
Por su lado, los modelos o1 (o1-preview y o1-mini) no pudieron recibir imágenes ni tener cambios en temperatura por restricciones en su API al momento de correr la evaluación.
Detalle de los resultados
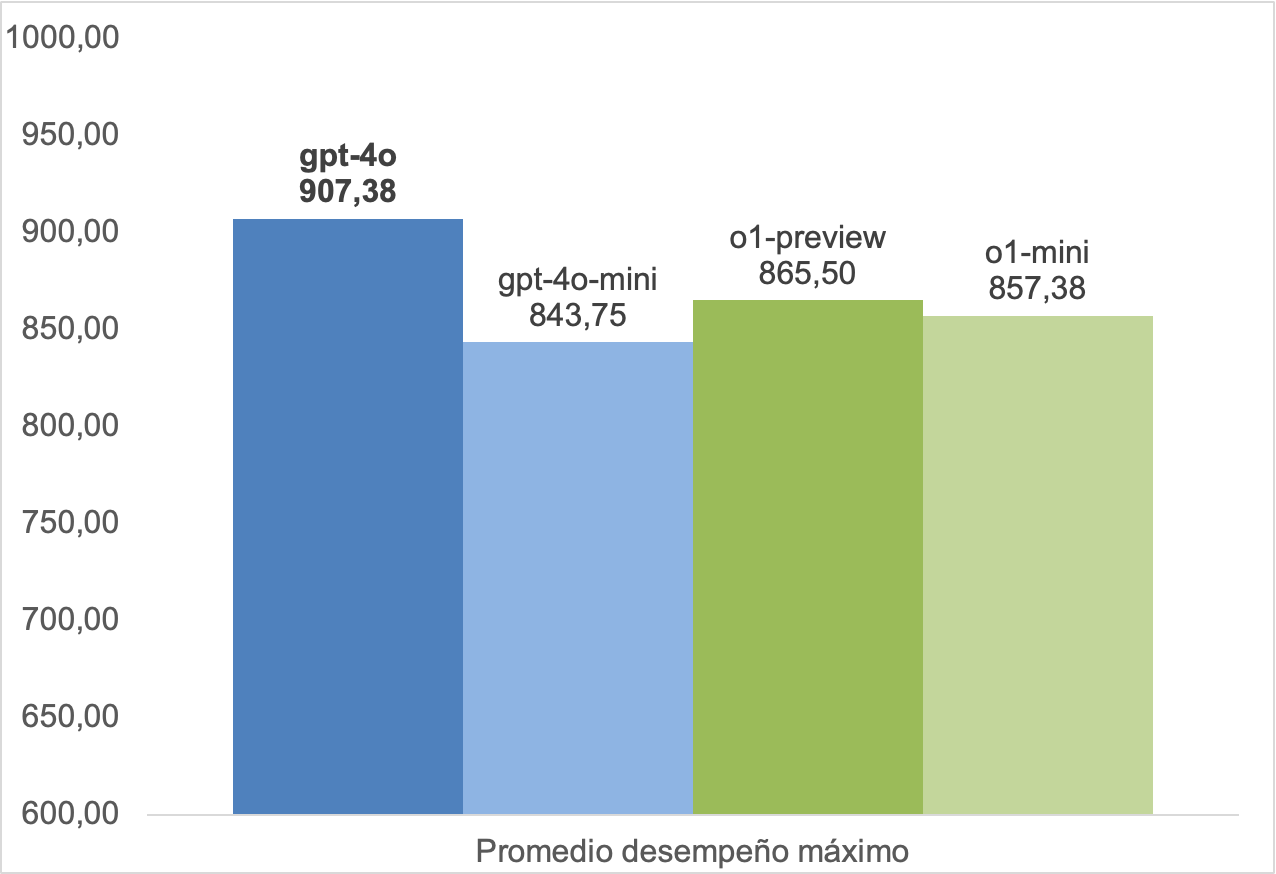
Desempeños máximos por modelo
Para evaluar los modelos utilizamos el desempeño máximo en cada prueba, pues de este modo podemos ver el potencial de cada modelo.

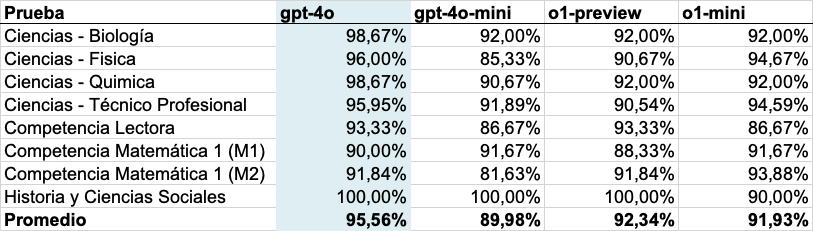
Estos resultados nos han sorprendido, dado que nuestra hipótesis inicial era que el modelo gpt-4o fuera peor que los modelos o1, especialmente en contenidos STEM por las fortalezas de los modelos, enunciadas por OpenAI.
En comparación con la edición 2024 de este experimento, el desempeño mejoró en las pruebas de Ciencias. En 2024 el promedio de las pruebas de Ciencias fue 769.25, mientras que en esta edición el promedio del desempeño máximo fue 909.25 (+18%) para el modelo gpt-4o y 830.25 (+8%) para o1-preview. En particular, en 2024 el desempeño general de los modelos era entorno al 81% - 87% en estas pruebas. Sin embargo, en esta edición el desempeño máximo subió a 96% - 98% en el modelo gpt-4o, y 91 - 92% en los modelos o1.
El desempeño matemático de los modelos ha mejorado en 2024. Sin embargo, no vemos esto reflejado en la evaluación, obteniendo un desempeño peor que lo que obtuvo GPT-4 el año pasado.
Desempeños promedio por modelo
Por su parte, si vemos el desempeño promedio de los modelos, el escenario cambia.
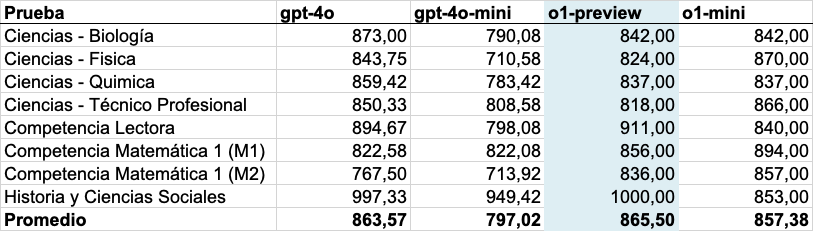
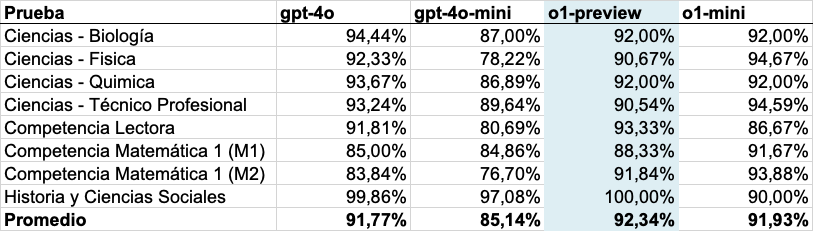
En esta visualización, el modelo gpt-4o ya no es el mejor, pero está muy cerca de o1, el modelo más sofisticado utilizado en el estudio.
No encontramos diferencias importantes en el desempeño de los modelos GPT con el cambio de las configuraciones del modelo.
Intervalos de Confianza de los Desempeños
El diseño de las evaluaciones, nos permite obtener un intervalo de confianza. Un intervalo de confianza es un rango de valores que nos dice qué tan seguros podemos estar de un resultado. Por ejemplo, en el caso de nuestras evaluaciones, el intervalo nos muestra entre qué puntos podría estar el verdadero desempeño de ChatGPT respondiendo la PAES, teniendo en cuenta posibles variaciones o errores en los datos. Es como un "margen de confianza" para interpretar los resultados.
Por otro lado, es importante tener intervalos de confianza, además de una estimación central, porque muestra si las diferencias en el desempeño entre modelos son reales o son solo cuestión de suerte, ayudando a evaluar sus capacidades de forma más clara y confiable.
De esta manera, los intervalos para los puntajes y el porcentaje de acierto se muestra a continuación.


De las tablas podemos inferir que, tal como vimos en los resultados en la sección anterior, gpt-4o supera a o1 en varias de las pruebas, pero además podemos inferir que la diferencia es estadísticamente significativa en Ciencias - Biología, Ciencias - Química, y Ciencias - Técnico Profesional.
Sobre los costos y tiempos
De los modelos o1-preview y o1-mini derivaron el 60% de los costos asociados a este experimento, mientras que de los modelos gpt-4o y gpt-4o-mini derivaron sólo el 40% de los gastos. Esto es sorprendente no sólo porque la precisión de los modelos o1 no fue muy superior a la serie de modelos gpt-4o, sino que también porque nuestra cantidad de pruebas en los modelos gpt-4o fue mucho mayor.
Esto está en línea con lo visto en las actuales aplicaciones de los modelos de razonamiento. En este podcast exploramos más sobre cómo o1 está habilitando nuevos casos de uso por su mayor precisión. Sin embargo, aún está el desafío de hacerlo a un costo razonable.
En cuanto a los tiempos, es normal que los modelos diseñados para razonamiento sean más lentos. Por ejemplo, el modelo o1-preview resultó ser, en promedio, 2,5 veces más lento que gpt-4o.
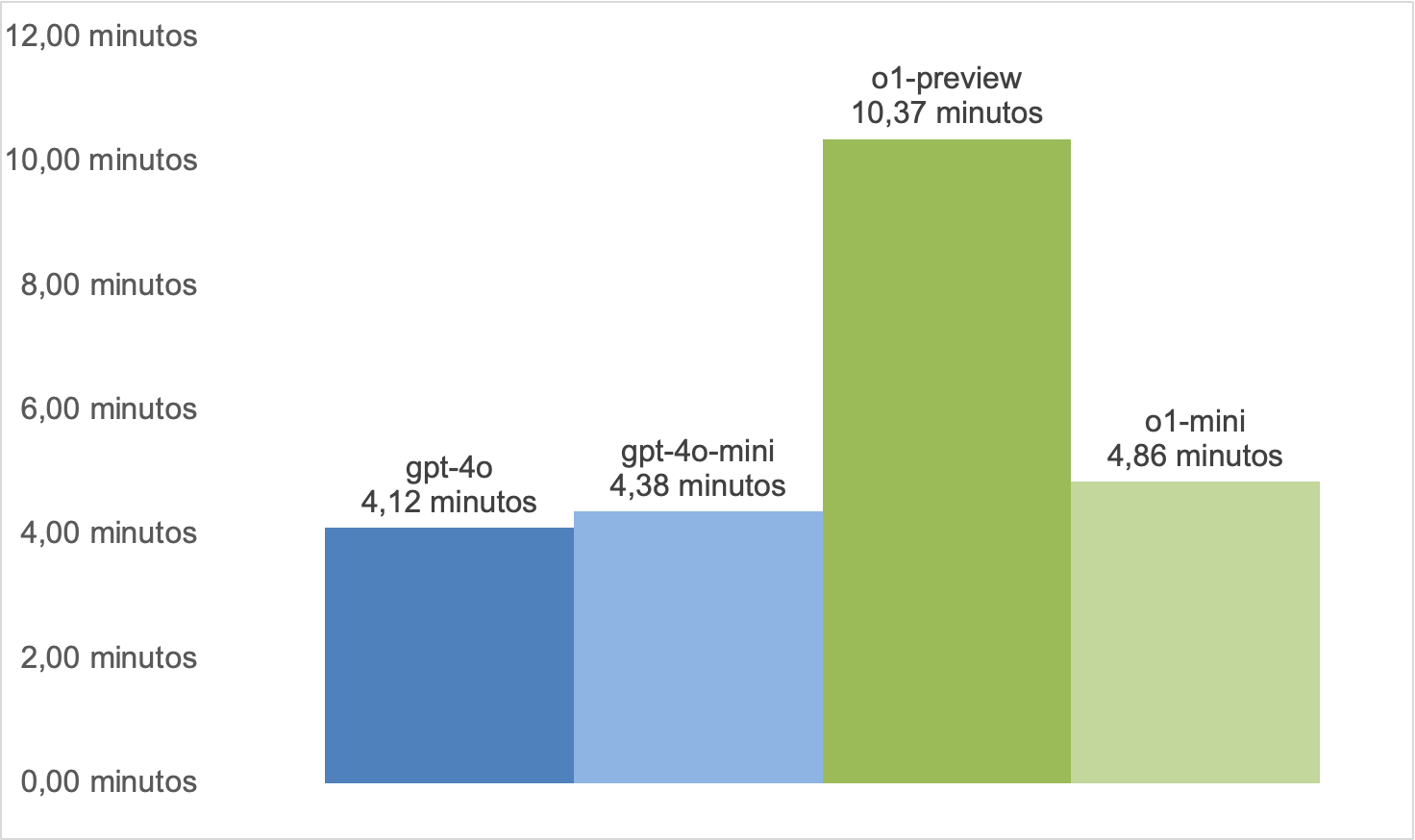
Adicionalmente, encontramos que las diferencias en tiempos entre modelos pueden ser aún más grandes dependiendo de cada prueba. En particular, la iteración más rápida de Competencia Lectora es 8,6 veces más rápida que la iteración más lenta.
Detalles de los tiempos
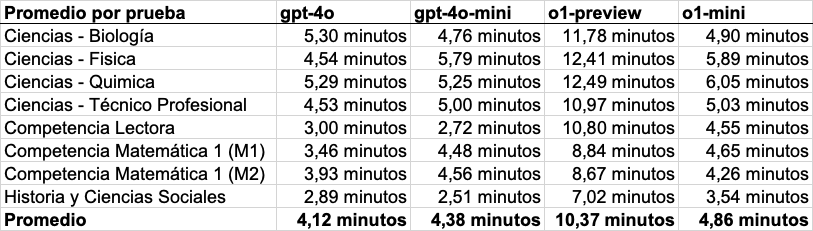
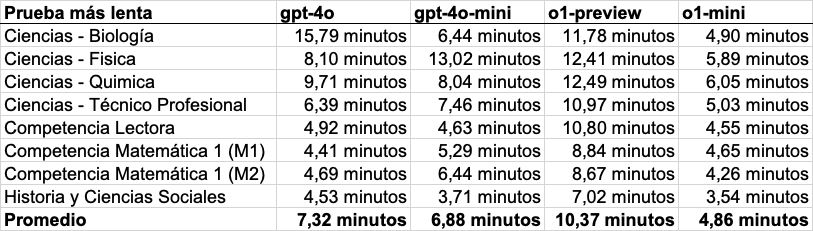
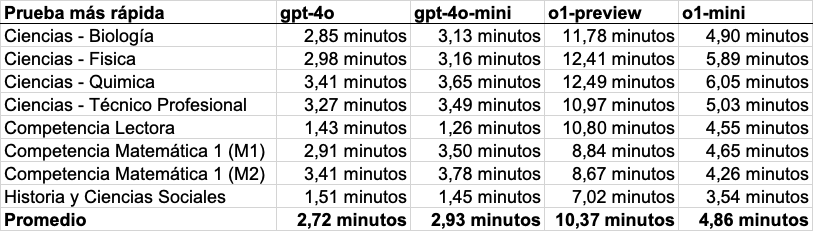
Finalmente, lo que no era esperado es que gpt-4o-mini tardara más en completar las pruebas que gpt-4o, pues el primero está pensado para interacciones rápidas según OpenAI. Esto fue observado aún cuando gpt-4o-mini fue más rápido procesando tokens (255 por segundo frente a 211 de gpt-4o), la unidad de medida usada en estos modelos para el largo de los inputs y outputs. En análisis más profundo, encontramos que esto se relaciona con la extensión de las respuestas: gpt-4o-mini procesó en promedio 61.732 tokens por prueba, mientras que gpt-4o procesó unos 48.691 tokens. Este hallazgo demuestra que un modelo puede ser rápido procesando texto/imágenes, pero su eficiencia en completar tareas, como responder una prueba PAES, depende también de la longitud de las respuestas que genera.
Carreras a las que entraría si fuera un estudiante
A continuación, dejamos una tabla resumen de a cuáles carreras podría o no ser seleccionado, en base a si su puntaje ponderado fuese mayor o no que el puntaje del último matriculado para esa carrera en 2024. Verde significa que supera el puntaje del último matriculado en 2024, mientras que rojo significa que no lo supera.
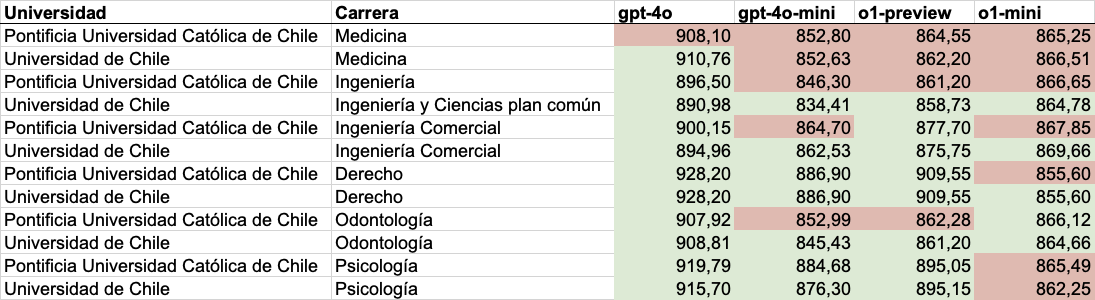
Esto es asumiendo que su NEM y Ranking de notas fueran similares a su desempeño en las pruebas.
Sobre EvoAcademy y los autores
En EvoAcademy nos dedicamos a la capacitación en temas de tecnología e inteligencia artificial. Revisa nuestros cursos para empresas aquí. Si quieres ponerte en contacto con nosotros escríbenos en este sitio web.
El trabajo técnico de este estudio fue realizado por Jonathan Vásquez, profesor adjunto de la Universidad de Valparaíso y Ph.D. in Computer Science de George Mason University, con apoyo de todo el equipo de EvoAcademy.
Te invitamos a revisar nuestro podcast de Inteligencia Artificial para los Negocios en este sitio web.
Preguntas frecuentes
Haz clic en las preguntas para expandir las respuestas
¿No es obvio que le debería ir muy bien si "es una gran base de datos"?
No. ChatGPT es está basado en un modelo de lenguaje enorme, un tipo de algoritmo computacional que lo que hace muy bien es predecir la siguiente palabra en base a lo dicho anteriormente.
A diferencia de otras funciones computacionales, como podría ser una consulta a una base de datos, no es capaz de dar una respuesta exactamente igual en el 100% de los casos, incluso dado la misma pregunta.
¿Le debería ir muy bien si puede ir a internet a buscar las respuestas?
Los modelos que utilizamos para estos cálculos no utilizan conexión a internet.
Dado que no sacó 100% en todo ¿No es que en realidad el ejercicio está mal programado?
Es normal que los modelos de lenguaje no obtengan puntajes perfectos en pruebas estandarizadas. Por ejemplo, en un estudio de OpenAI - la empresa detrás de ChatGPT - su modelo GPT-4 obtuvo sólo precisión de percentil 89, en una prueba similar a la PAES de matemáticas.
¿Qué es el modelo o1?
El modelo o1 es uno de los modelos más recientes de OpenAI. La gran diferencia con los modelos existentes es que "razona" antes de contestar. Este modelo está disponible en ChatGPT para aquellos que tienen licencias de pago.