
La IA ya puede entrar a cualquier carrera: ChatGPT, Gemini y DeepSeek compiten en la PAES 2026
Probamos ChatGPT, DeepSeek y Google Gemini en la PAES 2026. Descubre cuál ganó y qué implicancias tiene


En EvoAcademy sometimos a los modelos de Inteligencia Artificial más avanzados del mundo a la PAES Admisión 2026. Si bien la mejora es una constante anual, este año marca un punto de inflexión histórico: por primera vez, una IA ha obtenido el puntaje necesario para matricularse en cualquier carrera de cualquier universidad de Chile.
El panorama de la IA ha cambiado drásticamente en los últimos meses. ChatGPT ya no corre solo. Google (con Gemini) ha superando a OpenAI, y el modelo de código abierto DeepSeek ha irrumpido en el mercado demostrando que se puede competir con una fracción del costo.
En esta edición, nuestro estudio deja de enfocarse en un solo actor y pasa a un formato de comparación. La lógica es que, aunque todas estas plataformas parezcan “parecidas” para el usuario común, no fallan igual, no razonan igual y no son igual de consistentes. Por ello, los siguientes modelos contestaron la prueba:
- OpenAI: GPT-5.2 (versiones Instant y Extended Reasoning)
- Google: Gemini 3 Pro y Gemini 3 Flash
- DeepSeek: Versión 3.2 (Chat y Reasoner).
Para todos los proveedores, comparamos sus versiones "instantáneas" (optimizadas para velocidad) contra sus versiones "razonadoras" (que toman tiempo para "pensar" antes de responder).
Principales resultados
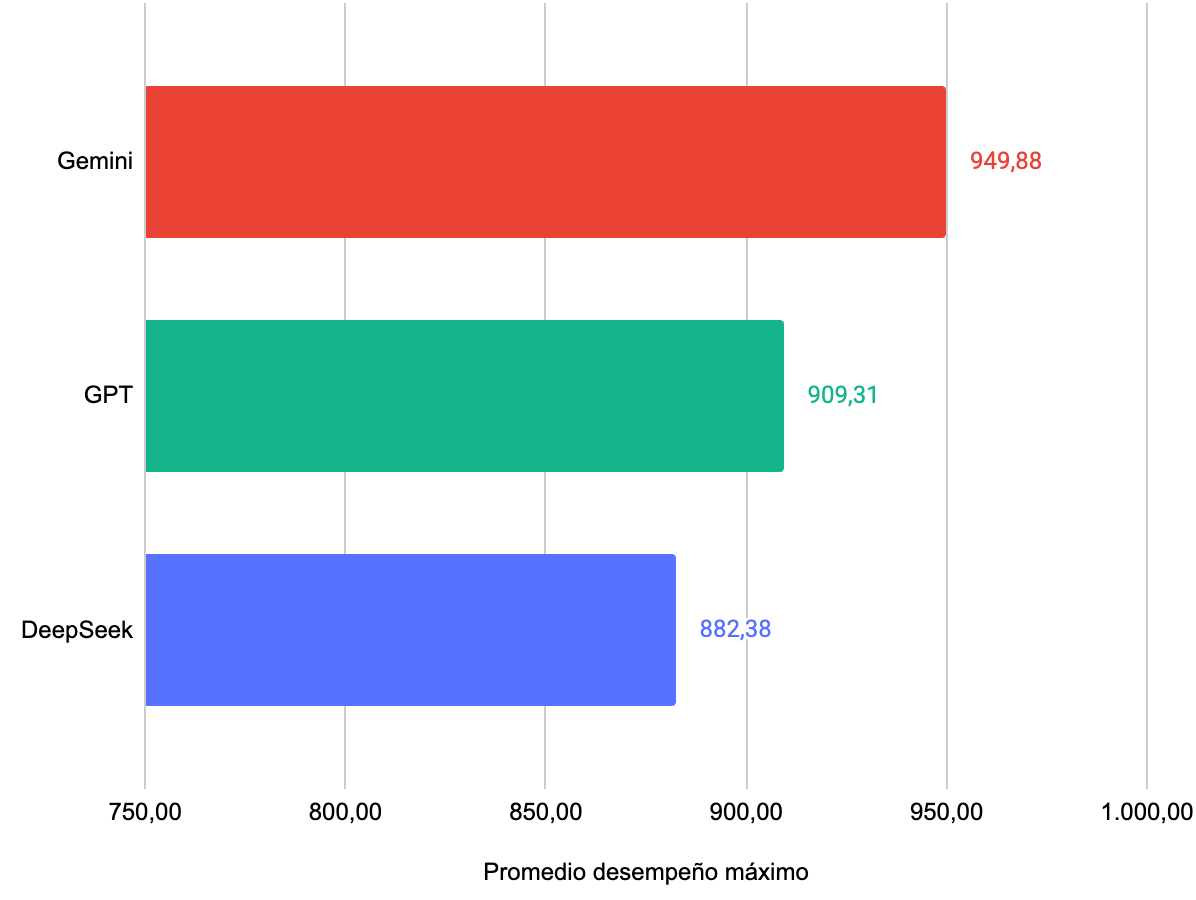
A continuación los principales resultados
- Google es el proveedor con mejor desempeño promediando 950 puntos entre sus modelos Flash y Pro.
- El mejor modelo es Google Gemini 3 Flash, el cual obtiene Puntaje Máximo (1.000 puntos) en cinco pruebas: Historia y Ciencias Sociales, Biología, Física, Competencia Lectora y Competencia Matemática 1 (M1) y un promedio de 957,38 puntos.
- Curiosamente, la versión Flash superó a la versión Pro. Aunque la diferencia no es estadísticamente significativa, demuestra que los modelos más ligeros y optimizados están alcanzando niveles de madurez sorprendentes.
- Ciencias sigue siendo algo complejo para la IA. Solo Gemini 3 Flash logró los 1.000 puntos en Biología y Física. Mientras que GPT bajó su rendimiento en Ciencias respecto al 2025, Google fue el único capaz de subir la vara en esta área, que sigue siendo el "Talón de Aquiles" de la IA.
- Todos los modelos lograron obtener 100% de precisión en la prueba de Historía y Ciencias Sociales. Lo que en 2025 parecía una hazaña de ChatGPT, hoy es el estándar de la industria.
- Si fuese un estudiante, Google Gemini 3 Flash y Pro podrían entrar a cualquier carrera de cualquier universidad del país. Esta es la primera vez que ocurre esto. Más detalles en la sección de Carreras.
Ve el detalle los resultados en esta sección.
Detalle de los resultados
Desempeño por modelo
Este fue el desempeño por cada modelo
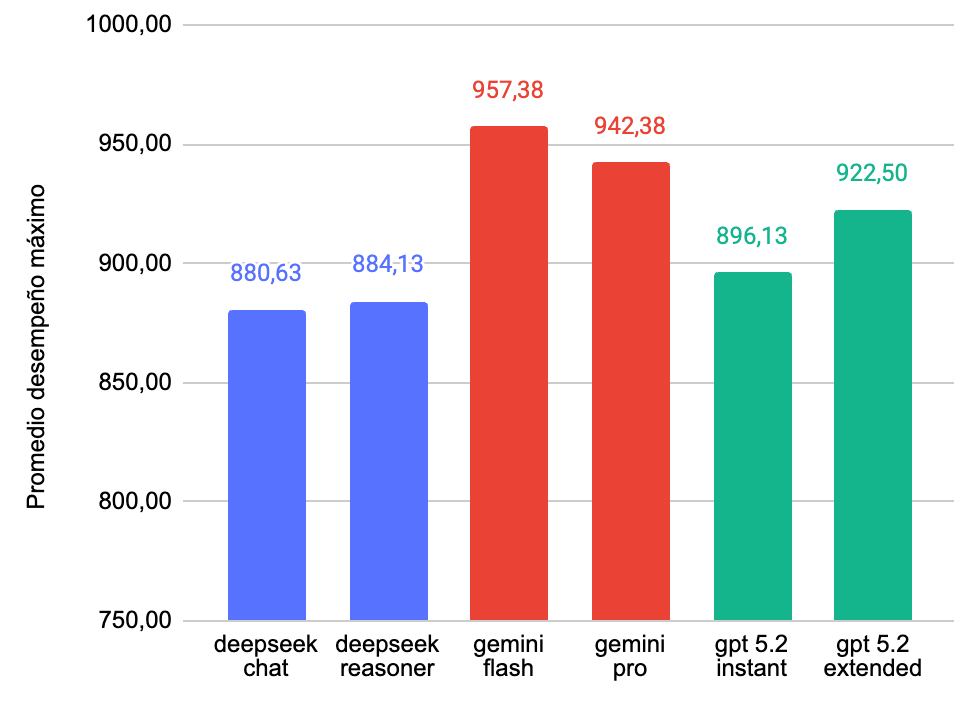
Al analizar las cifras en detalle, se confirman varias tendencias clave. En primer lugar, el liderazgo de Google Gemini 3 Flash es indiscutible, logrando la puntuación perfecta (1.000) en cuatro pruebas: Competencia Lectora, Matemática 1 (M1), Ciencias Biología, e Historia.
Otro punto crítico es la dificultad de Matemática 2 (M2). A diferencia de M1, donde los modelos líderes rozan la perfección, M2 actúa como un verdadero filtro de capacidad de razonamiento complejo: el puntaje del líder cae a 897, descendiendo hasta los 821 puntos en el caso de DeepSeek.
Finalmente, Historia aparece como un dominio completamente conquistado por la IA (todos los modelos obtienen 1.000 puntos).
Intervalos de Confianza de los Desempeños
Para asegurar que estos puntajes no son producto del azar, calculamos intervalos de confianza. Esta métrica nos permite estimar el "rango real" de habilidad del modelo, descartando que un buen puntaje sea solo "suerte" en preguntas específicas.
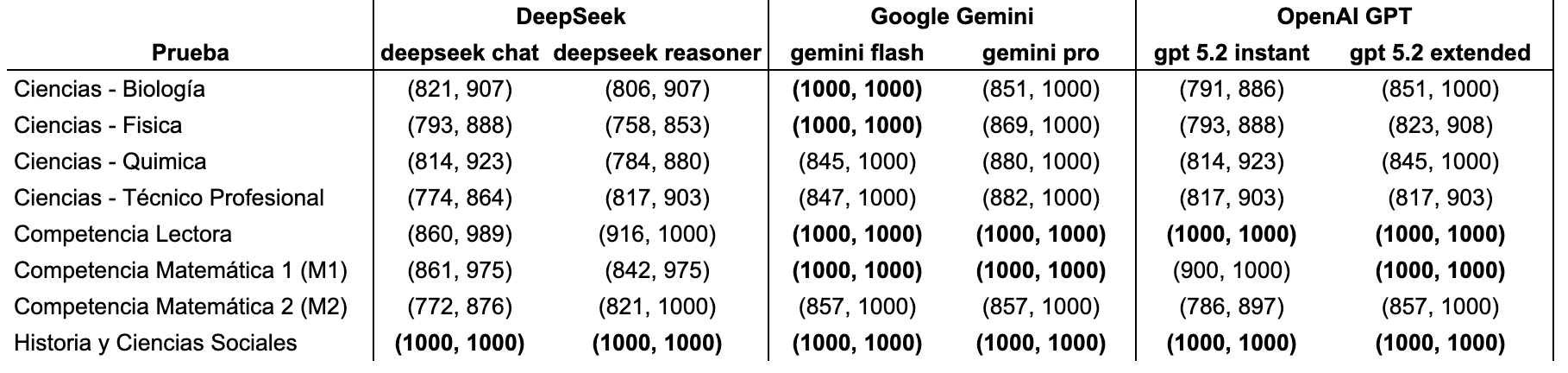
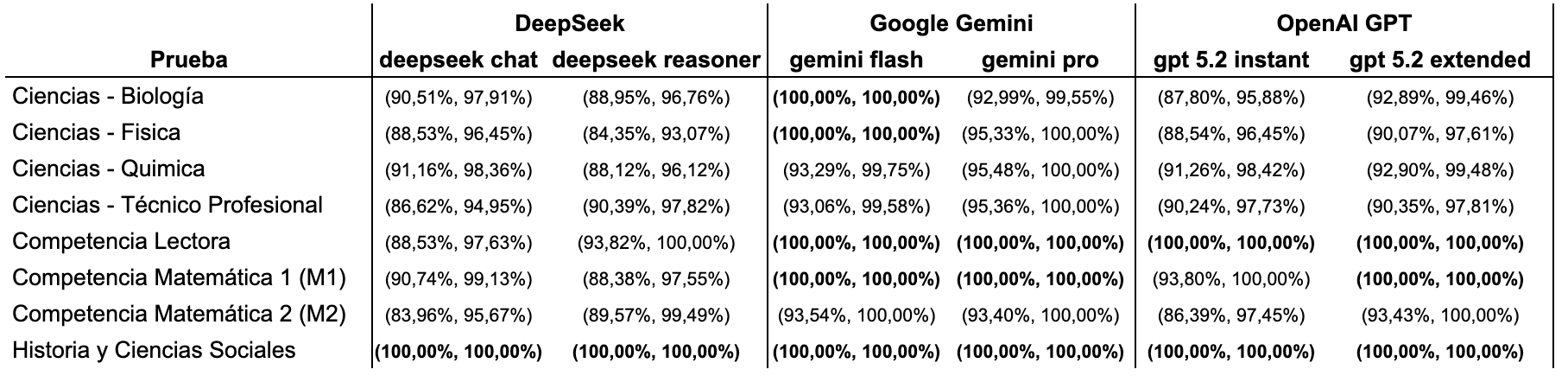
Al observar los intervalos (ver tabla), podemos ver que Google Gemini 3 Flash tiene el potencial real de haber obtenido puntaje perfecto en todas las pruebas, ya que su intervalo de confianza toca la cota superior (1.000) en cada medición. Por otro lado, aunque DeepSeek sorprende por su bajo costo, aún se mantiene distante en precisión respecto a los líderes del mercado estadounidense.
Preguntas en que no tiene buen desempeño
En las ediciones anteriores, las IAs brillaban en pruebas "humanistas" y sufrían en las científicas. Este 2026, la brecha se ha cerrado en matemáticas (M1) y lectura, donde los mejores modelos ya no presentan dificultades.
Sin embargo, Ciencias sigue la principal dificultad. En 2025, el promedio del desempeño máximo de GPT en las pruebas de Ciencias fue 909.25, pero este año fue sólo 858,25. Sólo Google Gemini experimenta una mejora, con 925,50 de promedio.
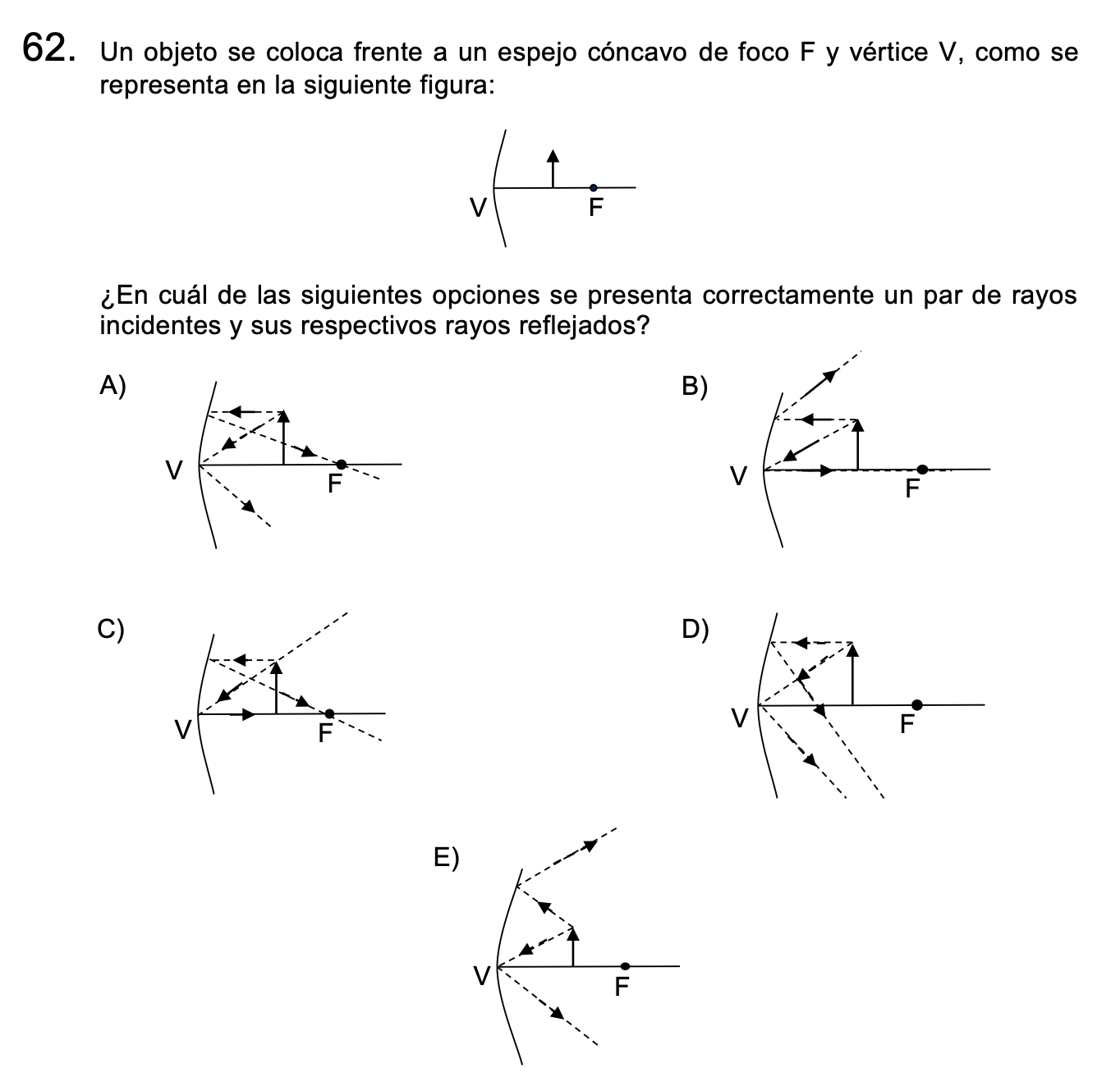
Por ejemplo, la pregunta 62 de Ciencias Físicas fue una de las más fallaron los modelos. Este es un buen ejemplo de pregunta dificil para la IA. Los modelos de lenguaje aún tienen muchas dificultades con temas espaciales
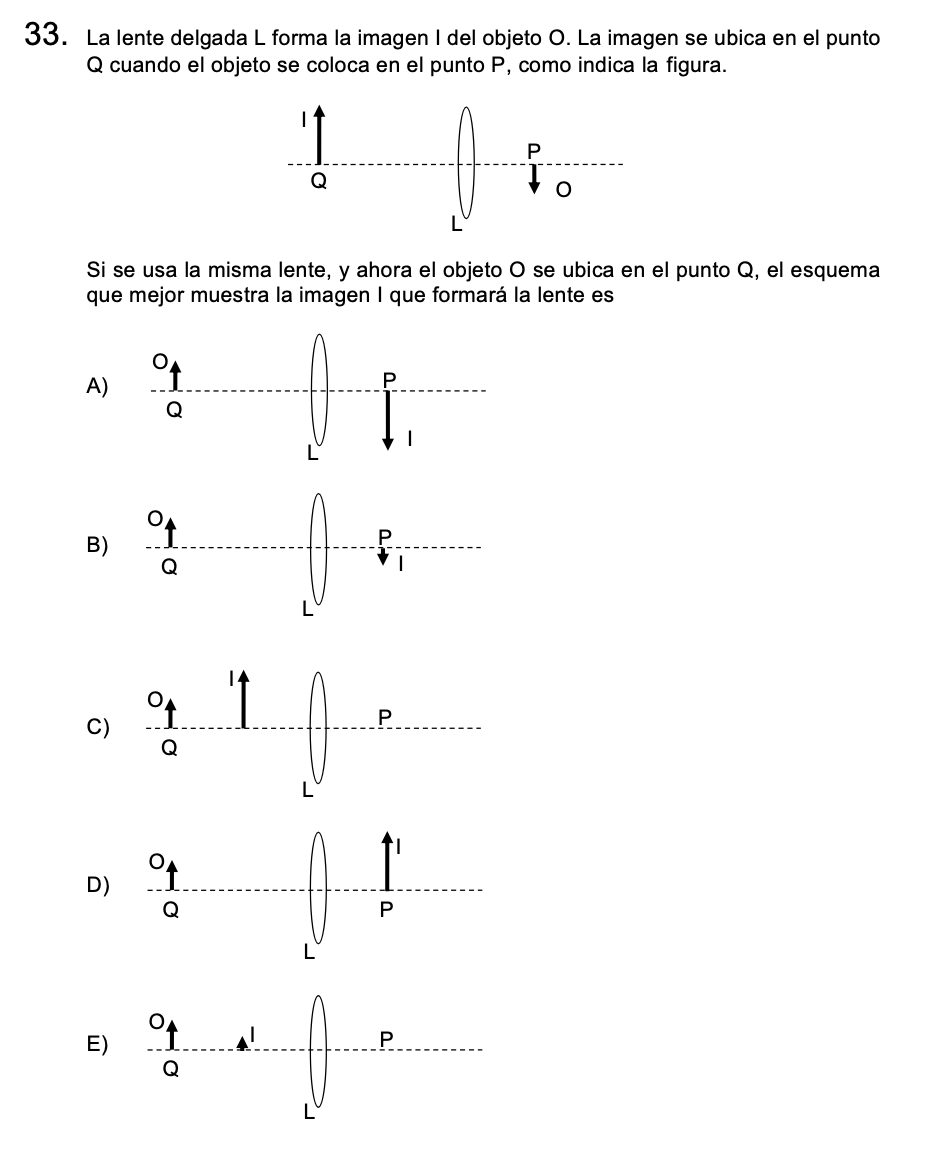
Otro ejemplo similar de preguntas con alto componente espacial es esta de la prueba de Ciencias - Técnico Profesional.
Costos y tiempo de procesamiento
Este año observamos una gran caída en los costos de procesamiento.
Para procesar las 8 pruebas completas, ningún modelo superó los $21 USD. Esto contrasta radicalmente con el experimento del año pasado, donde usar GPT-o1 costó más de $100 USD.

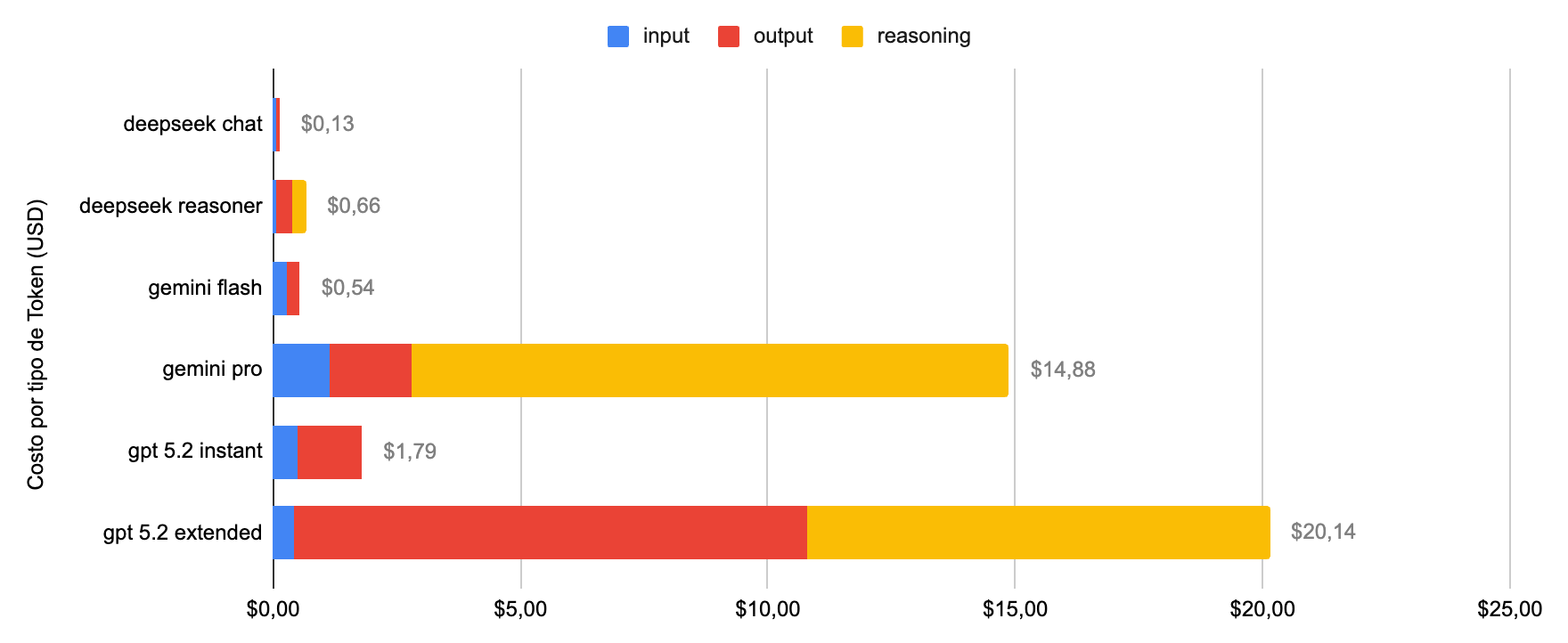
El gran ganador en costos es DeepSeek
- Es 14 veces más barato que GPT-5.2 en versiones rápidas.
- Es 30 veces más barato en versiones razonadoras.
Aunque su desempeño absoluto es menor al de Google y OpenAI, DeepSeek 3.2 ya supera al GPT del proceso de admisión anterior.
También cabe destacar que el costo del mejor modelo, Gemini 3 Flash, fue de apenas $0,4 USD. Para la misma tarea, el modelo razonador de Google tuvo un costo 27 veces mayor y no tuvo diferencias estadísticamente significativas en el desempeño.
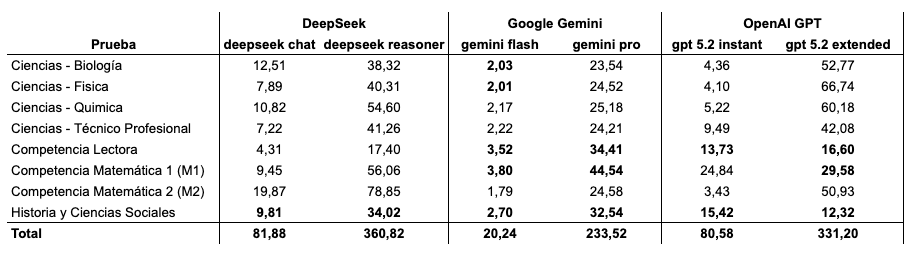
En relación a los tiempos, los modelos se pueden demorar desde menos 2 minutos hasta casi 79 minutos en responder una prueba completa. En general los modelos gastaron muy poco tiempo en Competencia Lectora.
Sin embargo, es importante señalar que este aspecto del estudio puede tener limitaciones pues la demora podría ser por la disponibilidad de los servidores de los proveedores y no realmente por la capacidad de computo. En particular, esta es nuestra sospecha con DeepSeek Reasoner, donde sus tiempos fueron bastante extensos pero su servidor está en China.
Carreras a las que entraría si fuera un estudiante
Si Google Gemini 3 Flash fuera un estudiante chileno, hoy podría matricularse en cualquier carrera de cualquier universidad del país.
En la siguiente tabla simulamos su postulación. Asumiendo un NEM y Ranking alineados con su promedio en las pruebas, comparamos su puntaje ponderado contra el último matriculado del proceso 2025.
- Verde significa que supera el puntaje del último matriculado en 2025
- Mientras que rojo significa que no lo supera.
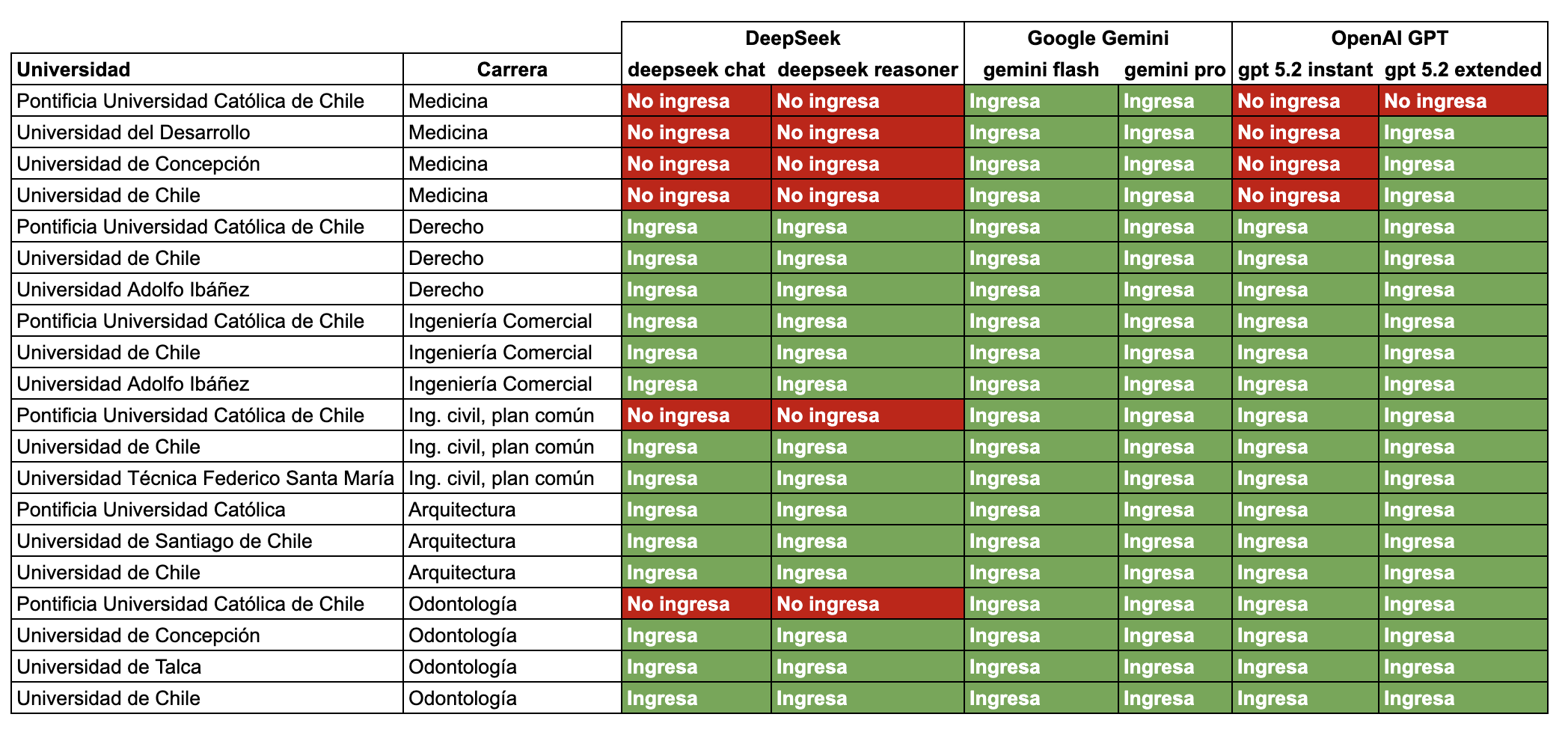
Esto es asumiendo que su NEM y Ranking de notas fueran similares a su desempeño promedio en las pruebas.
Sobre el estudio
Este análisis anual, iniciado en 2023 por EvoAcademy, mide la evolución de la inteligencia artificial frente a pruebas estandarizadas de acceso a la educación superior.
Utilizamos las pruebas oficiales del DEMRE para el proceso de Admisión 2026 (rendidas en diciembre de 2025). Dado que el DEMRE publica aproximadamente el 70% de las preguntas, utilizamos técnicas estadísticas como bootstrapping (con 100 iteraciones) para estimar el desempeño en la prueba completa.
Para casi todos los modelos corrimos el modelo más de una vez, con la excepción de GPT 5.2 en su versión Extended. Se seleccionó el intento con el desempeño máximo para cada modelo.
Puedes revisar aquí los resultados anteriores: PAES Regular 2025, PAES Regular 2024, PAES Invierno 2024 y la PAES Regular 2023
La PAES, o Prueba de Acceso a la Educación Superior, es un test estandarizado que se utiliza como parte del sistema de admisión en gran parte de las universidades en Chile. Para esta evaluación utilizamos las pruebas oficiales publicadas por el Departamento de Evaluación, Medición y Registro Educacional (DEMRE) para el proceso de Admisión regular 2025. Estas son las mismas pruebas que los estudiantes rindieron el 1, 2 y 3 de diciembre de 2025.
Sobre EvoAcademy y los autores
El estudio técnico fue liderado por Jonathan Vásquez, quien es Ph.D. in Computer Science, George Mason University y profesor Adjunto de la Universidad de Valparaíso, y Sebastián Cisterna, MBA de la Universidad de Harvard y Profesor de la Escuela de Negocios Universidad Adolfo Ibáñez, con el respaldo del equipo de EvoAcademy.
Nos dedicamos a capacitar empresas en la frontera de la tecnología. Si quieres llevar esta inteligencia a tu organización, contáctanos o escucha nuestro podcast "Inteligencia Artificial para los Negocios".
Preguntas frecuentes
Haz clic en las preguntas para expandir las respuestas
¿No es obvio que le debería ir muy bien si "es una gran base de datos"?
No. ChatGPT, Gemini y DeepSeek están basados en un modelo de lenguaje enorme, un tipo de algoritmo computacional que lo que hace muy bien es predecir la siguiente palabra en base a lo dicho anteriormente.
A diferencia de otras funciones computacionales, como podría ser una consulta a una base de datos, no es capaz de dar una respuesta exactamente igual en el 100% de los casos, incluso dado la misma pregunta.
¿Le debería ir muy bien si puede ir a internet a buscar las respuestas?
Los modelos que utilizamos para estos cálculos no utilizan conexión a internet.
Dado que no sacó 100% en todo ¿No es que en realidad el ejercicio está mal programado?
Es normal que los modelos de lenguaje no obtengan puntajes perfectos en pruebas estandarizadas.
Por ejemplo, en un estudio de OpenAI - la empresa detrás de ChatGPT - su modelo GPT-4 obtuvo sólo precisión de percentil 89, en una prueba similar a la PAES de matemáticas.
¿Qué es un modelo razonador?
Un modelo razonador es un LLM diseñado específicamente para "pensar" antes de responder.
A diferencia de los modelos estándar que predicen la siguiente palabra de forma casi instantánea (como un "reflejo"), un modelo razonador genera una cadena de pensamiento interna (Chain of Thought) antes de mostrar el resultado final.