
Aprende a programar en Python desde cero con Google Colab - parte 4. Estructuras de datos


En este artículo revisaremos qué cuales son los diversos tipos de datos que podemos manipular en python, cuáles son sus características, ventajas y desventajas.
En particular hablaremos de las listas, sets, diccionarios y tuplas.
Revisa todas las partes en nuestra categoría Aprende a programar.
Archivos
Encuentra aquí el Google Colab con los códigos de esta sesión. Si no sabes como instalar Google Colab, revisa este artículo.
Listas
Una lista es una colección ordenada de elementos, que están encerrados entre corchetes [ ]. Las listas son mutables, lo que significa que puedes cambiar su contenido.
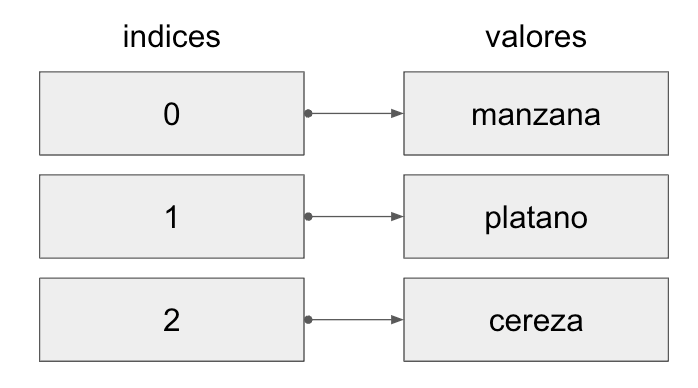
Por ejemplo:
frutas = ['manzana', 'platano', 'cereza']
frutas.append('naranja') # Podemos agregar un elemento a la lista
print(frutas) # Salida: ['manzana', 'platano', 'cereza', 'naranja']Métodos de manipulación
- append(elemento): Agrega un elemento al final de la lista.
- extend(iterable): Agrega todos los elementos de un iterable (como una lista o una tupla) al final de la lista.
- insert(index, elemento): Inserta un elemento en una posición específica de la lista.
- remove(elemento): Elimina la primera aparición de un elemento de la lista.
- pop(index): Elimina y devuelve el elemento en una posición específica de la lista. Si no se proporciona un índice, elimina y devuelve el último elemento.
- index(elemento): Devuelve el índice de la primera aparición de un elemento en la lista.
- count(elemento): Cuenta la cantidad de veces que un elemento aparece en la lista.
- sort(): Ordena los elementos de la lista en orden ascendente.
- reverse(): Invierte el orden de los elementos en la lista.
Conjuntos / Sets
Un conjunto es una colección no ordenada de elementos únicos. Son útiles cuando quieres llevar un registro de una colección de elementos, pero no te importa su orden, no te preocupan los duplicados y deseas realizar operaciones de conjuntos como unión e intersección. Los conjuntos están encerrados en llaves { }.
conjunto_frutas = {'manzana', 'plátano', 'cereza', 'manzana'}
print(conjunto_frutas) # Output: {'cereza', 'plátano', 'manzana'} (se eliminan los duplicados, el orden puede variar)Métodos de manipulación
- add(elemento): Agrega un elemento al conjunto. remove(elemento): Elimina un elemento del conjunto. Lanza un KeyError si el elemento no se encuentra. discard(elemento): Elimina un elemento del conjunto si está presente.
- pop(): Elimina y devuelve un elemento arbitrario del conjunto. Lanza un KeyError si el conjunto está vacío.
- clear(): Elimina todos los elementos del conjunto. union(otro_conjunto): Devuelve un nuevo conjunto con elementos del conjunto y todos los demás.
- intersection(otro_conjunto): Devuelve un nuevo conjunto con elementos comunes al conjunto y todos los demás.
- difference(otro_conjunto): Devuelve un nuevo conjunto con elementos en el conjunto que no están en los demás.
Diccionarios
Un diccionario es una colección no ordenada de pares clave-valor, donde cada clave debe ser única. Este tipo de datos es útil para almacenar relaciones entre pares de datos.
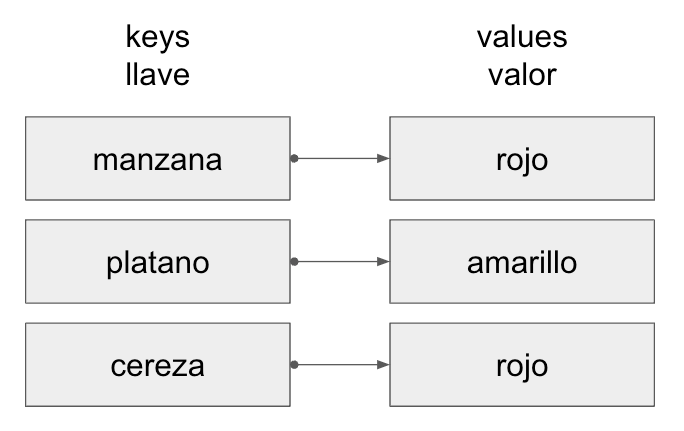
Los diccionarios también están encerrados en llaves { }, pero se distinguen por el uso de dos puntos : para separar las claves y los valores.
colores_fruta = {'manzana': 'roja', 'plátano': 'amarillo', 'cereza': 'roja'}
print(colores_fruta['manzana']) # Salida: 'roja'Métodos de manipulación
- keys(): Devuelve una nueva vista de las claves del diccionario.
- values(): Devuelve una nueva vista de los valores del diccionario.
- items(): Devuelve una nueva vista de los elementos del diccionario (pares clave, valor).
- get(clave, por_defecto): Devuelve el valor para clave si la clave está en el diccionario, de lo contrario devuelve por_defecto.
- update(otro_diccionario): Actualiza el diccionario con los pares clave/valor del otro, sobrescribiendo las claves existentes.
- pop(clave): Elimina y devuelve el valor para clave si la clave está en el diccionario.
Como evitar la confusion con los conjuntos
Tanto los diccionarios como los conjuntos se declaran usando corchetes { }, por lo que en el caso que declares un diccionario o conjunto vacio luego puedes generar una confusion. En tal caso, puedes declarar los diccionarios y conjuntos de modo explicito de esta manera
miConjunto = set()
miDiccionario = dict()Tuplas
Una tupla es una colección ordenada de elementos, similar a una lista. La diferencia significativa es que las tuplas son inmutables. Esto significa que una vez que se crea una tupla, no puedes cambiar su contenido. Las tuplas están encerradas entre paréntesis ( ).
tupla_frutas = ('manzana', 'plátano', 'cereza')
print(tupla_frutas[1]) # Salida: 'plátano'
# tupla_frutas[1] = 'pera' generaría un error porque no se pueden cambiar los elementos de una tuplaMétodos
Las tuplas son inmutables, por lo que no tienen métodos que agreguen o eliminen elementos. Sin embargo, tienen dos métodos:
- count(elemento): Devuelve el número de veces que un valor ocurre en una tupla.
- index(elemento): Devuelve el primer índice en el cual un valor ocurre en una tupla.
Tabla comparativa
Estas estructuras tienen características distintas que las hacen adecuadas para diferentes aplicaciones. Por ejemplo, si necesitas una colección de datos ordenada y mutable, las listas son ideales. Si quieres asociar valores con claves únicas, un diccionario es la mejor opción. Los conjuntos son perfectos para representar colecciones sin duplicados y para realizar operaciones de conjuntos, y las tuplas son ideales cuando necesitas una colección que no se pueda modificar.
La siguiente tabla resume las principales características de cada estructura de datos
| Característica | Listas | Diccionarios | Conjuntos | Tuplas |
|---|---|---|---|---|
| Orden | Ordenado | No ordenado | No ordenado | Ordenado |
| Tipo de dato | Secuencia | Mapeo | Conjunto | Secuencia |
| Sintaxis | [ ] | { clave : valor } | { elemento1, elemento2 } | ( ) |
| Mutabilidad | Mutable | Mutable (claves inmutables) | Mutable | Inmutable |
| Duplicados | Permite | No permite (claves) | No permite | Permite |
| Búsqueda por índice | Sí | No (búsqueda por clave) | No | Sí |
| Búsqueda por valor | Sí | Sí (búsqueda de valores) | Sí | Sí |
| Métodos principales | append, extend, remove | keys, values, items, get, update | add, remove, discard, union, intersection | count, index |
| Uso común | Almacenar secuencias | Almacenar pares clave-valor | Almacenar colecciones sin duplicados | Almacenar registros inmutables |
Funciones útiles para manipular este tipo de elementos
Existen algunas funciones que son muy útiles cuando manipulas este tipo de elementos.
La función len() te permite obtener cuantos elementos hay en la estructura. Por ejemplo:
estudiantes = ["Rodrigo", "Ignacio", "Nolan", "Jonathan", "Eduardo"]
len(estudiantes)
# resultado: 5La función str() la hemos usado antes para convertir elementos a String. Afortunadamente también funciona con las listas
estudiantes = ["Rodrigo", "Ignacio", "Nolan", "Jonathan", "Eduardo"]
str(estudiantes)
# resultado: ['Rodrigo', 'Ignacio', 'Nolan', 'Jonathan', 'Eduardo']Si tu estructura de datos contiene números también puedes usar max() y min() para obtener el máximo y el mínimo
calificaciones = [4, 3, 2, 4, 5]
max(calificaciones) #resultado: 5
min(calificaciones) #resultado:2Con la función map() aplicas una determinada función a cada item en una estructura de datos. Puedes convertir el resultado del map a una lista usando list().
En el siguiente ejemplo crearemos una función llamada square() que recibe un número y lo eleva al cuadrado. Esa función lo aplicaremos a nuestra lista de números usando map().
def square(x):
return x * x
numbers = [1, 2, 3, 4, 5]
squared_numbers = map(square, numbers)
print(list(squared_numbers))
# resultado: [1, 4, 9, 16, 25]Ejercicio: Eligiendo una estructura de datos
Suponga que usted fue elegido como asesor del código de una empresa y se encuentra con que la empresa almacena la información de sus productos de la siguiente manera
productos = ["Producto A", "Producto B", "Productoµ C"]
stock = [100, 50, 75]
precios = [10990, 5990, 8490]¿Cuál sería una mejor manera de almacenar datos? ¿por qué eligió esa manera?
# Diccionario para almacenar datos de productos
base = {
"Producto A": {"stock": 100, "precio": 10990},
"Producto B": {"stock": 50, "precio": 5990},
"Producto C": {"stock": 75, "precio": 8490}
}Esto es mejor por las siguientes razones:
- Integridad de datos: si eliminas un ítem en el diccionario, también eliminarás el resto de los datos relacionados con ese producto.
- Consistencia: todo está "adjunto" al mismo producto, así que si cambias un índice, todo también se moverá.
- Te ves obligado a agregar todos los datos relacionados de un producto.
- Sin duplicados: Los diccionarios tienen claves no duplicadas, por lo que puedes estar seguro de que solo hay un registro por producto.
- Legibilidad: Es más legible.
base["Producto B"]["stock"]es mejor queproducto[1]stock[1].
Cierre
Esto ha sido todo por nuestra introducción a Python con Google Colab. Es posible que expandamos esta guía si es que hay comentarios respecto a dudas o posibles mejoras, así que no dudes en dejar tu opinión si es que quieres ver nuevas ediciones :)
